3 Metodologia
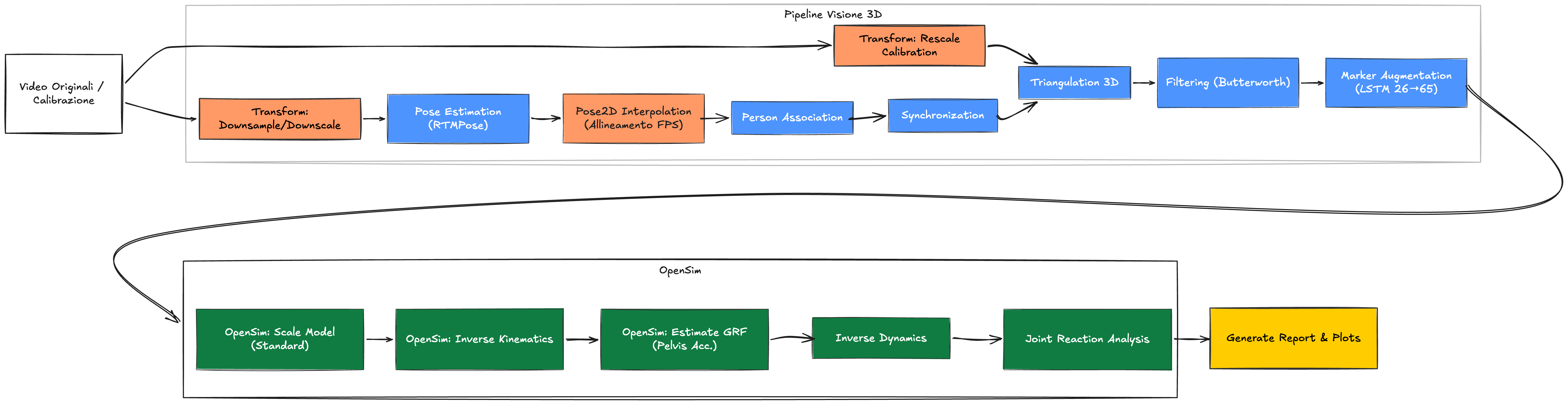
Questo capitolo descrive la metodologia della piattaforma biomeccanica sviluppata in questa tesi, dalla cattura video del movimento al calcolo delle forze articolari. La pipeline è organizzata attorno a un principio di modularità esplicita: ogni fase computazionale — preprocessing dei video, sincronizzazione delle camere, stima del movimento, scaling del modello muscoloscheletrico, analisi cinematica e dinamica — è implementata come unità indipendente con interfacce dati stabili e risultati persistiti su disco. Le sezioni che seguono analizzano sistematicamente ciascuno di questi step, la cui sequenza è sintetizzata nella Fig. 3.1 e nei relativi highlight che guidano il lettore attraverso il flusso completo.
3.1 Architettura della piattaforma
L’architettura della piattaforma estende il framework [@pagnon_2022_joss_pose2sim] attraverso un disaccoppiamento funzionale dei suoi componenti. Ogni stadio dell’elaborazione — dalla calibrazione iniziale alla Joint Reaction Analysis finale — opera come un’unità autonoma la cui interazione con il resto del sistema è mediata esclusivamente dal filesystem. La persistenza sistematica dei risultati intermedi su disco utilizzando formati standard non solo garantisce la tracciabilità del dato, ma rende la catena computazionale intrinsecamente modulare.
Questo paradigma consente la totale intercambiabilità delle implementazioni: è possibile, ad esempio, aggiornare il metodo di stima delle forze di reazione al suolo senza alterare i moduli di Inverse Kinematics o Dynamics a valle, a patto di rispettare i formati di interfaccia stabiliti. Su questa proprietà si basa il sistema di gestione delle varianti descritto nella Sezione 3.15, che riusa i nodi computazionali condivisi tra configurazioni diverse senza rieseguirli.
I dati seguono una gerarchia organizzata su quattro livelli: sessione, soggetto, trial e variante. Ogni livello ospita un file Config.toml con responsabilità semantiche distinte. Nella configurazione di sessione risiedono i parametri del contesto di acquisizione — telecamere, geometria del volume e calibrazione — comuni a tutti i soggetti della giornata. In quella di soggetto si trovano i dati antropometrici costanti, come massa e altezza. Nei file di trial e variante, infine, la configurazione eredita i parametri degli strati superiori sovrascrivendo unicamente le chiavi specifiche della prova, quali frame rate, risoluzione o metodo di stima delle forze.
La Fig. 3.1 sintetizza l’intera architettura della piattaforma come grafo orientato: ogni nodo rappresenta uno step computazionale, ogni arco un dato che ne costituisce l’interfaccia. Il flusso procede da sinistra a destra attraverso le seguenti fasi principali: acquisizione video multi-camera, conversione e organizzazione dei file, calibrazione del sistema di acquisizione, sincronizzazione delle camere, estrazione del trial di interesse, stima delle pose 2D, allineamento del frame rate tra camere, triangolazione 3D e marker augmentation, scaling del modello muscoloscheletrico, stima delle forze di reazione al suolo (GRF), Inverse Kinematics (IK), Inverse Dynamics (ID) e infine Joint Reaction Analysis (JRA). Ciascuno step è implementato come unità indipendente. I nodi in arancione identificano i moduli sviluppati integralmente nell’ambito di questo lavoro; i nodi in blu e in verde si riferiscono invece a strumenti esterni richiamati come sottoprocessi, rispettivamente Pose2Sim e OpenSim. Il diagramma evidenzia anche i nodi condivisi tra varianti: tutto ciò che precede lo step di GRF viene calcolato una sola volta per il trial base e riusato dalle varianti che differiscono solo nel metodo di stima delle forze.
Config.toml.
L’interfaccia tra due step adiacenti della pipeline è interamente definita dalla semantica dei dati che li separa. Lungo il flusso si distinguono alcune categorie concettuali: i dati grezzi di acquisizione (video multi-camera), le stime di posa bidimensionale per frame e per camera, le traiettorie tridimensionali dei marker nel tempo, gli angoli articolari risultanti dalla cinematica inversa, le forze esterne stimate e i momenti e le forze articolari prodotti dall’analisi dinamica. Ogni categoria corrisponde a un formato standard di settore, scelto per garantire interoperabilità con i tool esistenti dell’ecosistema biomeccanico.
Su questa infrastruttura stabile di pipeline si innesta il secondo componente del framework: il Variant Manager (Sezione 3.15). Il suo ruolo è concettualmente distinto da quello della pipeline — mentre la pipeline esegue deterministicamente una sequenza di step su un singolo trial, il Variant Manager coordina l’esecuzione di configurazioni alternative dello stesso trial per consentirne il confronto sistematico e la validazione reciproca.
La logica è la seguente: due varianti che differiscono solo nel metodo di stima GRF hanno in comune tutti i passi precedenti — calibrazione, pose estimation, triangolazione, scaling, IK. Il Variant Manager rappresenta questi passi come un singolo nodo nel DAG condiviso; i nodi successivi (GRF, ID, JRA) sono invece nodi distinti, uno per variante. Lo stato di ogni nodo è persistito in modo da rendere riprendibile l’esecuzione in caso di interruzione. Le dimensioni di variazione gestite — frequenza di campionamento, risoluzione video, metodo di scaling e metodo di stima GRF — generano nodi di tipo diverso a seconda della trasformazione richiesta.
Il nome della cartella di variante segue la convenzione trial_ZZ__tag1__tag2, dove i tag codificano le dimensioni di variazione rispetto al trial base — ad esempio trial_03__60fps__480p__com_model, che identifica la terza prova acquisita (trial_03), elaborata con un campionamento temporale a 60 fps, una risoluzione spaziale di 480p e l’impiego del modello basato sul centro di massa (com_model) per la stima delle forze di reazione al suolo; il Variant Manager li usa come chiavi di lookup nel DAG e aggiorna lo stato di esecuzione in file dedicati, così da ricostruire il grafo in qualsiasi momento senza rieseguire alcun calcolo. Lo scopo del sistema non è la mera replica dei dati, ma la possibilità di confrontare sistematicamente configurazioni diverse dello stesso trial per capire quali ottimizzazioni producono risultati comparabili alla versione ideale pur comportando vantaggi operativi — in termini di costi di acquisizione, tempo di elaborazione o semplicità del setup. Il sistema supporta anche l’esecuzione senza varianti: in quel caso il DAG degenera in una lista ordinata di step da eseguire sequenzialmente dall’acquisizione alla JRA, mantenendo tutta la struttura di tracciabilità e configurazione. L’architettura del DAG è descritta in dettaglio nella Sezione 3.15.
3.2 Acquisizione e setup sperimentale
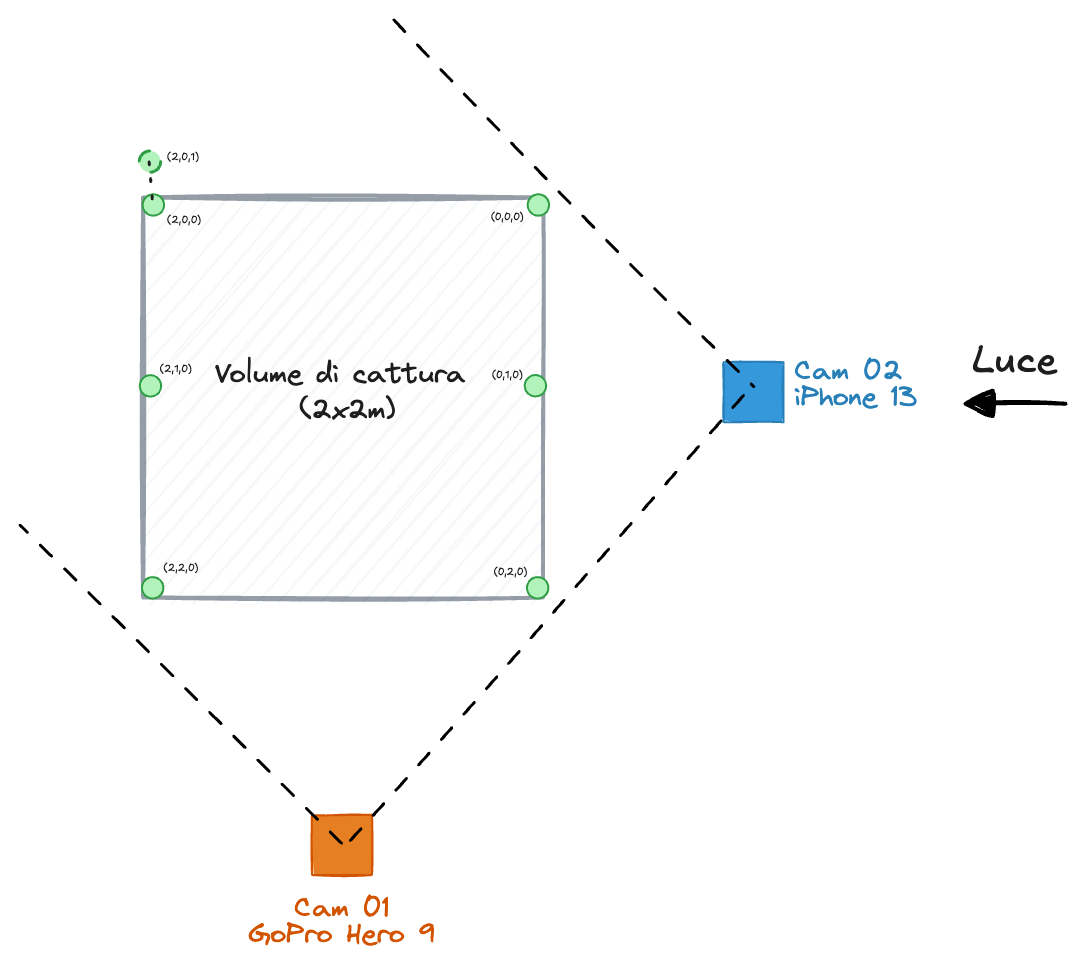
Le acquisizioni analizzate in questa tesi sono state effettuate con un sistema multi-camera interamente composto da dispositivi consumer, senza ricorrere a hardware specializzato. Le due telecamere impiegate sono un iPhone 13, fissato su cavalletto, e una GoPro Hero 9 Black, appoggiata su un mobile entrambi a un’altezza di circa 120 cm dal suolo. Entrambi i dispositivi sono stati configurati in modalità video lineare, escludendo correzioni ottiche di tipo grandangolare o zoom digitale: questa scelta è essenziale per garantire la compatibilità con il modello di camera a foro stenopeico (pinhole) su cui si basa la fase di calibrazione [@pagnon_2022_joss_pose2sim]. Il frame rate nativo delle due camere differisce leggermente: la GoPro acquisisce a 200 fps, mentre l’iPhone è stato impostato in modalità slow-motion nominale a 240 fps; la frequenza effettiva rilevata sui metadati del file risulta tuttavia pari a approx210.78 fps, una discrepanza tra valore dichiarato e valore reale che impone un passo dedicato di allineamento temporale post-pose (§Sezione 3.8). L’elaborazione dell’intera pipeline è stata eseguita offline su un MacBook Pro con chip Apple M2 Max e 32 GB di memoria unificata.
Le acquisizioni hanno coinvolto più soggetti. Il soggetto principale — un adulto di sesso maschile, 70 kg, 180 cm — è stato registrato nella sessione di riferimento e costituisce la base dell’analisi quantitativa presentata in questa tesi: su di lui è stata eseguita la pipeline completa nelle sue diverse varianti di configurazione. Sono stati acquisiti e analizzati anche tre soggetti di sesso femminile, con caratteristiche antropometriche diverse tra loro, registrati in una sessione separata. L’elaborazione di questi dati ha evidenziato una qualità inferiore nella stima delle pose bidimensionali rispetto al soggetto principale, con conseguente degradazione dei passi successivi della pipeline. I risultati ottenuti su questi soggetti saranno discussi nell’ambito delle limitazioni del sistema e delle prospettive di generalizzazione.
Le due telecamere sono state disposte attorno al soggetto con un angolo reciproco di circa 90°, secondo la raccomandazione consolidata per sistemi multi-vista a numero ridotto di camere [@pagnon_2022_joss_pose2sim]: questa geometria massimizza la separazione angolare delle viste e riduce l’ambiguità nella triangolazione tridimensionale dei keypoint parzialmente occlusi, come le articolazioni posteriori durante la fase di atterraggio del salto. Il volume di cattura risultante copre un’area a terra di circa 2 m × 2 m e si estende fino a 2.5 m in altezza, dimensioni sufficienti a contenere l’intera traiettoria del soggetto durante il Countermovement Jump, compresa la fase di volo.
La location scelta per le acquisizioni è una stanza esposta a nord, dotata di ampie finestre. L’orientamento nord garantisce una luce naturale costantemente diffusa, priva di irraggiamento diretto e di riflessi sulle ottiche: una condizione favorevole per la stabilità della pose estimation, che è sensibile a forti gradienti di luminosità e a variazioni rapide dell’esposizione. Nessuna fonte di illuminazione artificiale aggiuntiva è stata impiegata. La Fig. 3.2 illustra la disposizione planimetrica delle telecamere e il volume di cattura.
Durante la sessione sono stati eseguiti salti di tipologie diverse — con mani libere, con il supporto delle braccia al gesto atletico e con mani fisse sui fianchi — a piedi scalzi, con un intervallo di recupero non standardizzato tra un trial e l’altro. Il salto viene effettuato con attrezzatura sportiva come maglietta a maniche corte e pantaloncini corti. Ai fini dell’analisi biomeccanica e del confronto con i profili di riferimento della letteratura [@linthorne_2001_vertical_jump], vengono considerati esclusivamente i trial eseguiti nella modalità a mani sui fianchi, che corrisponde alla definizione standard del Countermovement Jump e garantisce la comparabilità della curva forza-tempo con i dati di riferimento.
3.3 Calibrazione
La calibrazione è il processo che determina i parametri geometrici e ottici del sistema di acquisizione, permettendo di convertire le coordinate dei pixel in coordinate metriche dello spazio 3D. Una volta acquisiti i video grezzi, è impossibile ricavare informazioni quantitative sulla posizione dei marker senza conoscere come ogni camera proietta lo spazio tridimensionale sul suo sensore. La calibrazione risponde a due domande distinte: in primo luogo, come ogni singola camera trasforma il 3D in 2D (calibrazione intrinseca); in secondo luogo, come i sistemi di riferimento delle diverse camere sono reciprocamente orientati e posizionati nello spazio (calibrazione estrinseca). La calibrazione intrinseca fornisce i parametri della geometria interna della camera — la lunghezza focale virtuale, il punto principale, i coefficienti di distorsione dell’ottica — e permette di applicare le trasformazioni proiettive corrette a ogni frame. La calibrazione estrinseca invece ancora tutti i fotogrammi a un sistema di coordinate metriche comune, prerequisito imprescindibile per la triangolazione 3D di §3.9 e per l’allineamento frame-per-frame fra camere di §3.8. Le due procedure sono logicamente separate ma complementari: entrambe sono eseguite una volta per sessione e il loro esito condiziona la qualità quantitativa di tutte le misurazioni successive.
La calibrazione intrinseca stima i parametri interni di ogni camera che descrivono come i punti dello spazio tridimensionale vengono proiettati sul sensore: nella formalizzazione del modello a foro stenopeico (pinhole) adottato da Pose2Sim [@pagnon_2022_joss_pose2sim], questo equivale a determinare la matrice \(K\) e i coefficienti di distorsione radiale e tangenziale dell’obiettivo.
Il pattern di riferimento scelto è una scacchiera rigida con geometria 7×10 (angoli interni: 6×9) e lato del quadrato di 27 mm: una configurazione che offre un buon compromesso tra densità dei punti di calibrazione e rilevabilità degli angoli a distanze operative di 1-3 m. La procedura di calibrazione prevede la registrazione di un video dedicato, girato prima di ogni sessione, durante il quale la scacchiera è presentata alla camera in 30-40 pose diverse — variando inclinazione, traslazione e distanza — per garantire una buona distribuzione angolare dei punti e ridurre la correlazione tra i parametri stimati. I frame estratti dal video sono elaborati da cv2.findChessboardCorners con raffinamento subpixel (cv2.cornerSubPix); i punti immagine così ottenuti alimentano cv2.calibrateCamera, che restituisce la matrice intrinseca
\[ K = \begin{bmatrix} f_x & 0 & c_x \\ 0 & f_y & c_y \\ 0 & 0 & 1 \end{bmatrix} \tag{3.1}\]
e il vettore di distorsione \([k_1, k_2, p_1, p_2, k_3]\) [@pagnon_2022_sensors_part1].
La calibrazione estrinseca determina la posizione e l’orientamento di ciascuna camera rispetto a un sistema di riferimento comune ancorato alla scena di acquisizione. Il sistema di riferimento adottato ha origine in un punto noto a terra (P1), con asse X orientato lateralmente, asse Y verso la profondità della scena e asse Z verticale — convenzionalmente coincidente con la direzione di salto.
La procedura si basa su sette punti di riferimento le cui coordinate tridimensionali sono note con precisione: sei punti (P1–P6) definiscono una griglia planare di 2 × 2 m a quota \(Z = 0\), con spaziatura di 1 m lungo entrambi gli assi; il settimo punto (P7) è posizionato a quota \(Z = 1\) m per vincolare l’asse verticale e rendere la soluzione di posa geometricamente determinata. Le posizioni dei punti sono marcate fisicamente nella scena con nastro adesivo colorato prima dell’acquisizione, e le relative coordinate reali in metri sono specificate nel file di configurazione Config.toml.
Per ciascuna camera, l’operatore identifica i sette punti su uno screenshot estratto dal video di scena e fa click sui punti nella sequenza fissa P1 → P7 tramite l’interfaccia di click interattivo. I punti 2D così raccolti e i corrispondenti punti 3D noti vengono passati a cv2.solvePnPRansac [@pagnon_2022_joss_pose2sim], che stima il vettore di rotazione \(\mathbf{r}\) (rappresentazione di Rodrigues, in radianti) e il vettore di traslazione \(\mathbf{t}\) (in metri) che descrivono la trasformazione rigida dalla scena alla camera. I parametri risultanti sono salvati nel file Calib.toml sotto le chiavi rotation e translation di ogni camera e rimangono invariati al variare della risoluzione di acquisizione, poiché dipendono esclusivamente dalla geometria fisica della scena.
Il reprojection error è la metrica principale per valutare la qualità della calibrazione: misura lo scarto in pixel tra la posizione osservata di un punto nell’immagine e quella ottenuta proiettando le sue coordinate 3D stimate attraverso il modello di camera calibrato [@pagnon_2022_joss_pose2sim] (Fig. 3.3).

Per la calibrazione intrinseca, cv2.calibrateCamera restituisce direttamente l’errore RMS di riproiezione sui punti della scacchiera: per la sessione_09 si ottiene 0.56 px su cam01 e 0.36 px su cam02, valori che indicano un’ottima qualità del fitting del modello pinhole (il criterio empirico di accettabilità comunemente adottato è RMS < 1 px). Per la calibrazione estrinseca, l’errore medio di riproiezione sui sette punti scena è 6.80 px: il valore è più alto rispetto all’intrinseca perché riflette sia l’imprecisione del click manuale sia il fatto che i sette punti campionano un volume 2 × 2 × 1 m invece del piano ravvicinato della scacchiera. Per il volume operativo e la precisione richiesta dalla biomeccanica del salto verticale, questo livello di errore estrinseco è ritenuto accettabile.
A valle della triangolazione Pose2Sim, il reprojection error dei keypoint — un indicatore indiretto della qualità calibrativa operativa — varia tra 4.6 px (dita del piede) e 9.1 px (anche) per gli arti inferiori, mentre per le articolazioni del tronco e degli arti superiori raggiunge 10–22 px a causa della maggiore variabilità della posa e della distanza dal volume calibrato. L’analisi quantitativa completa per trial e keypoint è riportata in Sezione 4.2.
I parametri della matrice \(K\) sono espressi in pixel e dipendono dalla risoluzione dell’immagine. Poiché la pipeline gestisce varianti di acquisizione a risoluzioni diverse (1080p, 720p, 480p), è necessario disporre di un file di calibrazione intrinseca specifico per ciascuna risoluzione. La soluzione adottata sfrutta il fatto che il downscale dei video è sempre isotropico, ottenuto tramite il filtro scale=-2:H di ffmpeg che preserva l’aspect ratio originale. In questo regime la relazione tra i parametri alle due risoluzioni è lineare ed esatta:
\[f_{x,\text{new}} = f_x \cdot \frac{W_\text{new}}{W_\text{orig}}, \quad f_{y,\text{new}} = f_y \cdot \frac{H_\text{new}}{H_\text{orig}}, \quad c_{x,\text{new}} = c_x \cdot \frac{W_\text{new}}{W_\text{orig}}, \quad c_{y,\text{new}} = c_y \cdot \frac{H_\text{new}}{H_\text{orig}}\]
I coefficienti di distorsione \([k_1, k_2, p_1, p_2, k_3]\) sono adimensionali e rimangono invariati; la medesima proprietà vale per i parametri estrinseci, che non dipendono dalla risoluzione. La funzione scale_calib_toml() applica questo rescaling a partire dal Calib.toml originale e scrive un file Calib_480p.toml nella cartella calibration/ del soggetto; ogni variante spaziale vi punta tramite symlink, così da non duplicare i dati di calibrazione. Come alternativa di verifica è disponibile anche una ricalibrazione diretta a partire dai frame del video di calibrazione originale ridimensionati alla risoluzione target, utile quando il rescale non è strettamente isotropico [@pagnon_2022_joss_pose2sim].
Il principale limite del metodo manuale a sette punti è la variabilità operatore-dipendente: l’imprecisione del click — stimabile in ±3–5 px su un’immagine a 1080p — si propaga direttamente nell’errore estrinseco e non è eliminabile senza un sistema di rilevamento automatico. Inoltre, la procedura richiede che tutti e sette i punti di riferimento siano contemporaneamente visibili da ciascuna camera, vincolando il posizionamento delle camere stesse.
Una calibrazione estrinseca automatica basata su marker ArUco è stata sviluppata e integrata nell’interfaccia Streamlit (calibra_aruco.py): il rilevamento dei corner dei marker avviene senza intervento manuale, riducendo la variabilità a quella della stima del centro del marker da parte di OpenCV. Questo approccio non è stato tuttavia impiegato nella sessione_09, poiché la sua validazione non rientrava nell’obiettivo primario di questa tesi; viene pertanto identificato come sviluppo futuro prioritario (Sezione 5.7).
Vale infine la pena segnalare che tutti i parametri rilevanti — geometria della scacchiera (numero di quadrati interni, dimensione del lato), coordinate 3D dei punti scena e soglie di accettazione — sono configurabili dall’interfaccia Streamlit senza modificare manualmente il file di configurazione e sono stampabili in pdf direttamente dall’interfaccia, riducendo la barriera tecnica per operatori non specializzati.
3.4 Preparazione e organizzazione dei video acquisiti
Al termine di ogni sessione di acquisizione, i file video si presentano in uno stato eterogeneo: ciascuna telecamera assegna ai propri file nomi generati automaticamente dal firmware — sequenze alfanumeriche prive di relazione con la struttura della sessione — e li salva in formati il cui profilo dipende dal dispositivo. Pose2Sim, che costituisce il nucleo della stima delle pose, si appoggia a OpenCV per la decodifica dei frame e richiede che i video siano in formato MP4/H.264 [@pagnon_2022_joss_pose2sim]; un file in formato diverso viene ignorato o letto in modo scorretto dagli step a valle, rendendo incompatibile con la pipeline qualsiasi sorgente non normalizzata.
La preparazione affronta due problemi distinti. Il primo è la conversione al formato compatibile: i file che non rispettano il requisito vengono ri-codificati con il codec H.264 a qualità costante (CRF 15), una configurazione che preserva la qualità spaziale senza introdurre artefatti percettibili. Ugualmente critica è la preservazione del frame rate originale: un downsampling o un upsampling involontario della frequenza di campionamento in questa fase introdurrebbe errori sistematici nelle traiettorie cinematiche a valle, poiché l’intera catena di analisi dipende dalla cadenza con cui il moto è stato registrato. Il secondo problema è la rinomina: in questo modo ogni file riceve un nome canonico e prestabilito derivato dalla convenzione gerarchica della sessione, in modo che ciascuno step possa individuare i propri file video tramite percorsi deterministici e senza logica di ricerca.
Tutto il processo opera su una cartella di acquisizione dedicata all’interno della struttura gerarchica della sessione; i file depositati in questa cartella costituiscono il punto di ingresso dell’intera pipeline, e ogni step a valle lavora esclusivamente su materiale già normalizzato.
La conversione al formato compatibile si concentra su MP4/H.264, requisito imprescindibile per Pose2Sim che utilizza OpenCV per la decodifica dei frame [@pagnon_2022_joss_pose2sim]. H.264 è una scelta consolidata sia teoricamente — introduce efficienze significative nei meccanismi di prediction e reference frame management [@wiegand_2003_h264_standard] — che praticamente, mantenendo l’equilibrio migliore tra efficienza di compressione e compatibilità del decoder rispetto a codec più recenti come HEVC e AV1 [@uhrina_2024_codec_comparison]. I file non conformi vengono ri-codificati tramite ffmpeg con libx264 a qualità costante (CRF 15, preset medium) — configurazione che preserva la qualità spaziale per vision tasks [@otani_2022_action_recognition_quality] — preservando la traccia audio in AAC a 256 kbps (riferimento primario per la sincronizzazione inter-camera, §Sezione 3.5) e mantenendo il frame rate originale per evitare errori sistematici nelle traiettorie cinematiche.
L’operazione è progettata per essere idempotente: la funzione assicurati_mp4() verifica se il file MP4 di destinazione esiste già; in caso affermativo, l’operazione di transcodifica viene saltata; in caso negativo, il file viene transcodificato e depositato nella stessa cartella.
La pipeline è costituita da due fasi sequenziali ma concettualmente distinte. La prima è il preprocessing: standardizzazione dei file video grezzi, sincronizzazione temporale fra le viste, estrazione della porzione temporale di interesse (un singolo trial). La seconda è l’elaborazione delle varianti: per uno stesso trial, generazione di multiple elaborazioni (IK, ID, JRA) con parametri diversi (fps, risoluzione, metodo GRF). Queste due fasi vivono in spazi logici separati per una ragione fondamentale: il preprocessing non conosce a priori come il trial sarà decomposto o elaborato, e l’elaborazione deve riusare senza duplicazione i risultati del preprocessing [@pagnon_2022_joss_pose2sim; @molder_2021_snakemake].
La cartella video_sessione/ costituisce la zona di preprocessing, collocata direttamente alla radice della sessione. È qui che confluiscono tutti i file prodotti dalle fasi §3.4 e §3.5: i video convertiti in H.264, i video sincronizzati, il file metadata.json che traccia la storia di ogni operazione. Questa zona è stabile: una volta che un file è depositato qui, non viene mai spostato, duplicato o modificato da step successivi. È l’unico spazio su cui il preprocessing_tool ha permesso di scrittura.
Le cartelle soggetto_XX/trial_YY/videos/ costituiscono invece la zona di elaborazione, creata on-demand durante il passo di estrazione (§3.6). Le clip estratte vengono copiate (non spostate) dalla zona di preprocessing nella loro cartella di destinazione. Questa indirezione — preprocessing scrive in una zona, elaborazione legge da una zona diversa — è il meccanismo che permette di estrarre lo stesso video in trial differenti, o di rieseguire l’estrazione senza toccare mai i file sorgente. È il principio di modularità: ogni step dichiara esplicitamente i suoi input e output, senza effetti collaterali su step precedenti.
La convenzione di naming non è un elenco di suffissi, ma un contratto fra step. Ogni step della pipeline conosce dove trovare i propri input e dove depositare i suoi output perché i percorsi sono determinati da regole sintattiche globali applicate uniformemente a ogni livello della gerarchia.
Le cartelle di sessione e soggetto seguono uno schema a due cifre con zero-padding (sessione_09, soggetto_01): l’ordine numerico riflette la cronologia di acquisizione e garantisce l’anonimizzazione. I file video mantengono nomi fissi per camera (cam01.mp4, cam02.mp4), assegnati dall’operatore e utilizzati da ogni step per identificare le viste. Dopo la sincronizzazione, il suffisso .sy. viene aggiunto (cam01.sy.mp4), segnalando il completamento della fase.
Le cartelle di trial seguono lo schema trial_ZZ__tag1__tag2__..., dove il doppio underscore è un delimitatore riservato che separa l’indice del trial dai tag di variazione. Questo delimitatore consente il parsing sistematico dei tag a livello di DAG: ogni step che elabora una variante sa quali parametri applicare leggendo i tag dal nome della cartella. Senza questo vincolo sintattico, il sistema di varianti descritto in Sezione 3.15 non potrebbe costruire dipendenze fra nodi e riusare computazioni comuni. Il naming standardizzato è quindi la pre-condizione che rende la pipeline riusabile fra sessioni diverse: una volta che il preprocessing di sessione_09 è completo, una nuova sessione può applicare le stesse regole di naming, beneficiando di un’infrastruttura di step già validata e riusabile.
Ogni operazione di preprocessing registra la propria traccia in un file metadata.json collocato nella cartella video_sessione/. Questo file svolge il ruolo di registro unico dello stato di preprocessing per la sessione: contiene la lista delle conversioni effettuate (con timestamp, file sorgente, formato originale e parametri di codifica), la lista delle sincronizzazioni (con l’offset temporale applicato e le camere coinvolte) e la lista degli split eseguiti (con gli intervalli temporali e le destinazioni). La struttura è additiva: ogni operazione viene appesa alla lista corrispondente, senza sovrascrivere le voci precedenti preservando lo storico di tutte le operazioni fatte.
I Config.toml descrivono la configurazione del sistema — parametri di acquisizione, antropometria del soggetto, opzioni della pipeline — mentre metadata.json descrive le operazioni eseguite, ovvero cosa è stato fatto, quando e con quali parametri. Questa separazione permette al sistema di verificare, prima di agire, se un’operazione è già stata completata, rendendo possibile la ripresa in caso di interruzione senza rieseguire passi già portati a termine.
Il principio di idempotenza attraversa tutti i passi di preprocessing: prima di agire, ciascun passo interroga il metadata.json per stabilire se l’operazione è già stata portata a termine, leggendo le informazioni necessarie alle fasi successive. Se l’operazione è già registrata, il passo viene saltato; in caso contrario, l’operazione viene eseguita e il suo risultato viene aggiunto al registro. Questa capacità di essere riprendibile senza effetti collaterali costituisce il fondamento dell’efficienza dell’intero sistema di varianti descritto in §3.15, dove i nodi computazionali condivisi sono eseguiti una sola volta.
3.5 Sincronizzazione delle registrazioni
Nei sistemi di cattura del movimento di laboratorio la sincronizzazione è garantita a livello hardware: un segnale di trigger condiviso — o, nei sistemi più avanzati, il genlock — forza tutti i sensori a esporre simultaneamente, eliminando alla radice qualsiasi disallineamento temporale tra le viste [@jackson_2016_argus_audio_sync; @hasler_2009_async_cameras]. Le fotocamere consumer, tuttavia, non supportano questa modalità: GoPro e iPhone vengono avviati manualmente e in modo indipendente, producendo un offset temporale arbitrario tra i due flussi video — non misurabile a priori e variabile da acquisizione ad acquisizione.
Questo disallineamento non è un dettaglio trascurabile. La triangolazione 3D presuppone che i frame di camere diverse corrispondano al medesimo istante fisico: se una camera è in anticipo di \(k\) frame rispetto all’altra, ogni punto ricostruito nello spazio combina le pose del soggetto catturate in istanti diversi. A 200 fps ogni frame rappresenta 5 ms; uno scarto di soli 0.5 frame produce un incremento dell’errore di riproiezione di circa 0.54 pixel e può amplificare gli errori sulle accelerazioni articolari fino al 15% [@jackson_2016_argus_audio_sync]. È quindi necessario stimare e applicare un offset temporale tra i due flussi.
Per fornire un riferimento temporale comune, l’operatore esegue un singolo clap — mano che colpisce mano — in campo visivo di entrambe le camere immediatamente prima dell’inizio di ogni sessione di acquisizione. L’evento è simultaneo per definizione e produce segnali distinguibili su due canali fisicamente indipendenti.
Sul canale audio, il clap genera un transient impulsivo con onset inferiore al millisecondo: un picco di energia acustica estremamente stretto, ideale come ancora per la stima del ritardo temporale tramite cross-correlazione [@jackson_2016_argus_audio_sync]. Sul canale visivo, il movimento del polso che si abbassa e risale produce un picco di velocità nei keypoint 2D stimati dalla pose estimation; questo secondo segnale non è tuttavia disponibile come input primario dell’algoritmo — la stima di posa richiede frame già grossolanamente allineati — e viene impiegato come verifica a posteriori nell’interfaccia di validazione descritta in §3.5.4.
La ridondanza tra i due canali aumenta la robustezza complessiva: se il canale audio risulta degradato — per esempio in ambienti rumorosi o su telecamere configurate in modalità silenziosa — il segnale visivo offre un ancoraggio alternativo per la validazione manuale [@hasler_2009_async_cameras]. La stima algoritmica dell’offset si appoggia comunque al segnale audio.
L’algoritmo di sincronizzazione opera in due fasi distinte. Nella prima, la funzione estrai_audio() invoca ffmpeg per estrarre il canale audio di ciascun video come array NumPy mono a 44 100 Hz; a questa frequenza di campionamento ogni campione copre circa 23 µs, una risoluzione temporale di due ordini di grandezza inferiore alla durata di un singolo frame a 200 fps [@jackson_2016_argus_audio_sync].
Nella seconda fase, trova_picchi() calcola l’energia RMS del segnale su finestre scorrevoli di 512 campioni e ne prende il logaritmo in decibel, ottenendo un profilo di loudness che rende comparabili segnali con livelli di registrazione diversi. Su questo profilo scipy.signal.find_peaks cerca i massimi locali con prominenza minima di 3.0 dB, distanza minima tra picchi di 0.5 s e un massimo di 30 candidati per traccia. Il picco con la prominenza più alta nella finestra iniziale della registrazione viene identificato come istante del clap, \(t_\text{clap}\), per quella camera.
L’offset temporale proposto è quindi
\[\Delta t = t_{\text{clap,A}} - t_{\text{clap,B}}\]
dove il segno indica quale flusso è in anticipo. Il valore rimane espresso in secondi fino all’export, in cui viene convertito in frame interi sulla base dell’fps nativo di ciascuna camera.
Poiché un offset errato si propaga senza attenuazione a tutte le fasi successive — triangolazione, IK e analisi dinamica — il sistema non persiste mai il valore di \(\Delta t\) senza una conferma esplicita dell’operatore. Il workflow è progettato per rendere questa validazione rapida: meno di trenta secondi per acquisizione.
Dopo il calcolo automatico descritto in §3.5.3, l’interfaccia Streamlit visualizza le due waveform RMS in dB sovrapposte e allineate secondo il \(\Delta t\) proposto (Fig. 3.4). La coincidenza visiva dei picchi del clap è il primo criterio di accettazione. Accanto alla waveform, l’interfaccia mostra in parallelo i frame estratti a \(t = \Delta t\) dalle due camere: l’operatore può scorrere l’intorno di ±N frame e verificare che la posa del soggetto — in particolare la posizione del polso usata come riferimento visivo in §3.5.2 — sia coerente tra le due viste.
Se la proposta automatica non è soddisfacente, uno slider permette di correggere \(\Delta t\) in passi da un millisecondo o frame per frame, aggiornando in tempo reale entrambe le visualizzazioni. Solo dopo la conferma esplicita l’offset diventa parte dello stato della sessione e l’allineamento viene materializzato sui file video.
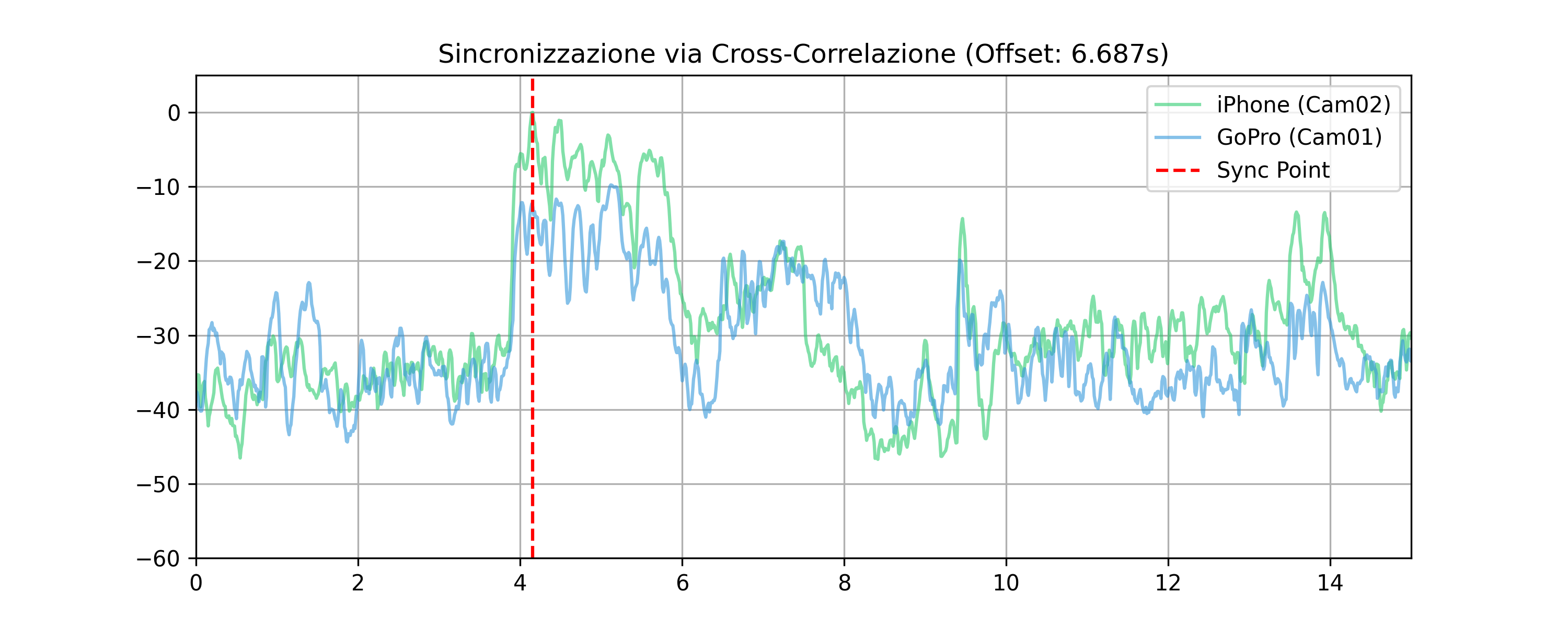
Dopo la conferma dell’operatore, il pipeline produce due output distinti. Sul piano dei metadati, l’offset \(\Delta t\) viene aggiunto alla lista syncs in video_sessione/metadata.json, insieme al timestamp dell’operazione, alla modalità fps scelta, ai percorsi dei video coinvolti e all’fps nativo rilevato per ciascuna camera; questo record è la fonte di verità da cui tutte le fasi successive leggono l’allineamento temporale della sessione.
Sul piano dei file video, i due flussi vengono ri-encodati e scritti come <nome>.sy.mp4 nella cartella video_sessione/, con parametri ffmpeg fissi (CRF 15, codec libx264 preset slow, audio AAC 256k). I file .sy.mp4 sono l’input fisico di tutti i passi a valle: lo split dei trial in §3.6 opera direttamente su di essi, così i clip estratti partono già al frame zero comune senza che ogni fase successiva debba gestire un offset residuo. Questo passo risolve un offset intero dovuto alla differenza di istante di avvio tra le due registrazioni; la differenza di frequenza di campionamento — GoPro a 200 fps e iPhone a circa 210.78 fps — è affrontata separatamente in §3.8.
3.6 Estrazione dei trial dalla registrazione continua
Ogni sessione di acquisizione produce un’unica registrazione continua per camera: N salti eseguiti in sequenza, separati da pause di durata variabile, senza alcun segnale automatico che demarca l’inizio e la fine di ciascun trial. Prima di procedere con la pose estimation e la triangolazione è necessario estrarre ogni salto in una clip separata, con indici di frame che partono da zero e un nome che segue la gerarchia di §3.4.
Il taglio non richiede precisione al singolo frame: un margine di qualche decina di frame prima dello stacco e dopo l’atterraggio è sufficiente per tutte le analisi a valle, e un clip leggermente più lungo del minimo non causa errori. Il costo principale del taglio manuale è il tempo su sessioni con venti o più salti, non la precisione.
All’apertura della pagina di split, una barra temporale orizzontale mostra i tagli già confermati nella sessione corrente: ogni trial estratto in precedenza appare come un segmento colorato sulla durata totale del video di riferimento. Questo riepilogo permette all’operatore di interrompere il lavoro e riprendere in un secondo momento senza perdere il contesto, e di verificare immediatamente che nessun salto sia stato saltato o duplicato.
Per ciascun nuovo trial, l’operatore seleziona la finestra temporale tramite uno slider di range sincronizzato con campi di input numerici in secondi; a entrambi gli estremi viene mostrata un’anteprima del frame corrispondente, così è possibile verificare visivamente che la clip inizi prima dello stacco e termini dopo l’atterraggio con il margine desiderato. La clip viene quindi etichettato con il soggetto e il trial di destinazione, selezionabili tra quelli già esistenti nella sessione o creabili al momento; il nome del trial segue la convenzione gerarchica della sessione. La conferma avvia l’estrazione fisica.
Alla conferma dell’operatore, il sistema invoca ffmpeg su tutti i file .sy.mp4 presenti in video_sessione/, estraendo la stessa finestra temporale \([t_\text{start},\, t_\text{end}]\) da ciascuna camera. Poiché i file sorgente sono già allineati secondo l’offset calcolato in §3.5, i clip risultanti mantengono la corrispondenza frame-per-frame. L’estrazione utilizza re-encoding anziché stream copy per garantire un inizio esattamente al frame scelto; il flag -avoid_negative_ts make_non_negative previene timestamp negativi che potrebbero corrompere la lettura dei clip da parte di OpenCV. I clip vengono scritti nella cartella soggetto_YY/trial_ZZ/videos/ e ogni estrazione viene registrata nella lista splits di video_sessione/metadata.json.
Insieme ai clip video, lo split istanzia nella nuova cartella di trial un file Config.toml che integra il trial nella gerarchia di configurazione descritta in §3.1.2. Il file generato è deliberatamente minimale: contiene soltanto l’identificatore del trial e, quando previsti, i tag di variante che lo distinguono dal trial base; tutti gli altri parametri — antropometria del soggetto, configurazione delle telecamere, geometria del volume di misura — non vengono replicati e sono risolti a tempo di esecuzione risalendo la gerarchia fino al livello in cui sono definiti.
Questa scelta non è un dettaglio organizzativo ma una proprietà strutturale della piattaforma: una modifica della massa o dell’altezza del soggetto si propaga automaticamente a tutti i suoi trial e a tutte le varianti che ne discendono, senza che sia necessario aggiornare manualmente i singoli file di configurazione. Lo stesso meccanismo di stub gerarchici è ciò che rende possibile aggiungere varianti dello stesso trial — diverse per frame rate, risoluzione o metodo di stima — senza duplicare i parametri di soggetto e di sessione: ciascuna variante è descritta dal solo insieme di chiavi che la distinguono dalla configurazione ereditata.
Al termine dell’estrazione la cartella di trial contiene quindi i clip allineati e un Config.toml integrato nella gerarchia, pronta a essere consumata dagli step di pose estimation che seguono.
3.7 Pose estimation 2D
La stima della posa 2D è il primo vero stadio di elaborazione dei fotogrammi di un trial nella pipeline: a partire dai frame grezzi di ogni camera, produce per ciascun soggetto le coordinate pixel dei keypoint anatomici che alimenteranno la triangolazione 3D. Il modello adottato è RTMPose [@jiang_2023_rtmpose], un estimatore multi-persona a schema top-down sviluppato nell’ecosistema MMPose di OpenMMLab e progettato per coniugare accuratezza di livello accademico con velocità di inferenza compatibile con applicazioni industriali e cliniche.
Lo schema top-down prevede due stadi in cascata: un detector di persone individua prima le bounding box di ogni soggetto nel frame, poi un estimatore di posa dedicato opera sul ritaglio di ciascuna bounding box producendo la stima dei keypoint. Rispetto all’approccio bottom-up — che localizza prima tutti i keypoint nell’immagine e li aggrega a posteriori — il top-down garantisce stime più robuste per soggetti singoli e mantiene l’accuratezza al crescere della risoluzione del crop; il prezzo è una complessità computazionale che scala linearmente con il numero di soggetti, un costo accettabile nei nostri setup a uno o due soggetti.
La colonna portante della rete RTMPose è basata sull’architettura CSPNeXt (Cross Stage Partial Network con blocchi depthwise e large-kernel convolutions): le convoluzioni a kernel allargato approssimano il campo ricettivo globale dei vision transformer senza gli oneri computazionali e di memoria dell’attenzione multi-testa, permettendo il deployment della rete su hardware consumer — CPU x86, GPU CUDA, e backend Apple Silicon MPS — a frequenze >= 100 fps, compatibili con la cadenza di acquisizione dei video ad alta velocità utilizzati nell’analisi del salto verticale. L’addestramento impiega il lisciamento ponderato esponenziale dei pesi (EMA weight smoothing) per stabilizzare la convergenza e ridurre la varianza delle stime nei frame caratterizzati da transizioni cinematiche rapide.
La componente più distintiva dell’architettura è il modulo di stima della posa SimCC [@li_2022_simcc], che sostituisce le classiche deconvoluzioni su mappe di calore 2D con due problemi di classificazione 1D indipendenti — uno per l’asse orizzontale e uno per quello verticale. Ciascun asse è suddiviso in \(k \cdot D\) bin discreti (dove \(D\) è la dimensione originale in pixel e \(k > 1\) è un fattore di sovracampionamento), e la posizione del keypoint è predetta come distribuzione di probabilità su questi bin mediante entropia incrociata con regolarizzazione label smoothing. L’uso dell’entropia incrociata con label smoothing — una tecnica che regolarizza la funzione di perdita non penalizzando indiscriminatamente i bin falsi, ma pesando i bin adiacenti secondo una distribuzione (gaussiana, laplaciana o uniforme) — cattura implicitamente la continuità spaziale senza operazioni di sovracampionamento: il modello apprende che la probabilità deve concentrarsi intorno al valore vero e decrescere verso i bin lontani.
Il risultato è una localizzazione sub-pixel ad altissima fedeltà: l’errore di quantizzazione a gradino (stair-stepping) che affligge le pipeline heatmap-based viene eliminato, e le traiettorie dei keypoint nel tempo sono abbastanza regolari da sopravvivere alla doppia derivazione temporale richiesta dalla stima dell’accelerazione del centro di massa. Questa proprietà, apparentemente di dettaglio implementativo, ha un impatto diretto sulla qualità delle forze di reazione al suolo stimate a partire dalla cinematica (§Sezione 3.12): con un head heatmap classico, il rumore di quantizzazione sul segnale di posizione si amplifica quadraticamente nella seconda derivata e sopravvive anche a filtri passa-basso aggressivi. SimCC, eliminando gli artefatti di gradino a livello di tracciato 2D, consente alla pipeline di leggere il segnale di accelerazione senza contaminazione quantizzata.
La validità di RTMPose per l’analisi del salto verticale è supportata da @aleksic_2024_cmj_validation, che confrontano esplicitamente un pipeline RTMPose-based con un sistema optoelettronico Qualisys a 100 Hz su soggetti atletici impegnati nel CMJ: la correlazione tra le traiettorie verticali del CoM è \(r \approx 0{,}999\), con RMSE della dislocazione verticale di circa 0,02 m — comparabile all’artefatto da tessuti molli tipico dei sistemi marker-based — e ICC > 0,91 su tutte e nove le fasi di salto analizzate.
Il formato di keypoint scelto per l’intera pipeline è HALPE_26 [@fang_2023_alphapose_halpe], una tassonomia che estende il COCO-17 standard con nove punti anatomici aggiuntivi: l’apice della testa (head top), il collo, il centro anatomico del bacino e, soprattutto, sei keypoint del piede per lato — alluce (BigToe), mignolo del piede (SmallToe) e tallone (Heel), bilaterali. In MMPose, questa configurazione corrisponde alla modalità Body_with_feet.
La motivazione della scelta è funzionale e percorre verticalmente l’intera pipeline. I sei keypoint del piede sono indispensabili in tre punti distinti: nel rilevamento automatico degli eventi di salto (Sezione 3.6), dove il toe-off è identificato tramite la traiettoria verticale del tallone e dell’alluce e non sarebbe estraibile da un formato senza questi punti; nella fase di marker augmentation (Sezione 3.9), dove la rete LSTM pre-addestrata su Pose2Sim si aspetta in input i 26 keypoint HALPE come feature e produce i 65 marker virtuali compatibili con il modello OpenSim; e nella fase di Inverse Kinematics (Sezione 3.11), dove l’assenza di keypoint al piede porta sistematicamente agli artefatti foot-skate e candy-wrapper — il piede scivola sul suolo o ruota in modo non fisiologico — che contaminano tutti i gradi di libertà della catena cinematica.
La consistenza del formato lungo tutta la pipeline è non negoziabile [@fang_2023_alphapose_halpe]: una singola fase che produca output in COCO-17 — per esempio perché un modello è stato cambiato senza aggiornare la configurazione downstream — genera un disallineamento silenzioso degli indici dei keypoint. Il disallineamento non produce un errore esplicito ma propaga coordinate sbagliate attraverso la triangolazione, l’augmentation e l’IK, rendendo i risultati invalidi senza un segnale diagnostico evidente. Per questo motivo, il parametro pose_model è fissato a Body_with_feet in tutti i file di configurazione e verificato programmaticamente all’avvio di ogni step della pipeline.
L’inferenza RTMPose è gestita dal backend MMPose ed è eseguita separatamente per ciascuna camera, producendo per ogni video un file JSON con le stime di posa frame per frame. Il backend supporta tre modalità di esecuzione — CUDA per GPU NVIDIA, MPS per GPU Apple Silicon e CPU pura — con selezione automatica basata sull’hardware disponibile; la compatibilità multi-backend consente di eseguire la stessa pipeline sia su workstation con GPU dedicata, sia su laptop con chip Apple Silicon, sia su hardware senza accelerazione grafica, garantendo portabilità senza modificare il codice di elaborazione [@jiang_2023_rtmpose].
Per ogni frame, il modello restituisce una lista di detection, ciascuna composta da una bounding box con score di confidenza e da un array di 26 keypoint nella forma \([x, y, \text{conf}]\), dove \(x\) e \(y\) sono le coordinate in pixel nel sistema di riferimento del frame originale e \(\text{conf} \in [0,1]\) è la probabilità di visibilità stimata dalla rete. I valori di confidenza per keypoint sono l’unica metrica di qualità disponibile a questo stadio e vengono propagati nelle fasi successive: la triangolazione li usa come pesi nel calcolo DLT, e i keypoint con confidenza sotto soglia vengono sostituiti da NaN prima di procedere, così da non contaminare la ricostruzione 3D con stime inaffidabili.
Il file JSON per camera costituisce l’interfaccia dati tra la fase di pose estimation 2D e tutti gli step successivi; la sua struttura è fissa e dipende esclusivamente dal formato HALPE_26 e dalla risoluzione di acquisizione, rendendo il file interpretabile da qualsiasi step downstream indipendentemente dal modello specifico usato per generarlo — proprietà utile per sostituire RTMPose con modelli futuri senza modificare la pipeline a valle.
La person association — stabilire quali detection nelle diverse viste corrispondono allo stesso soggetto fisico — è un passo necessario prima della triangolazione. Pose2Sim gestisce questo problema tramite un algoritmo di clustering spaziale che ragruppa le detection cross-camera in base alla coerenza geometrica delle proiezioni epipolar, assegnando a ciascun cluster un identificatore di soggetto persistente nel tempo [@pagnon_2022_joss_pose2sim].
Nel caso più comune di un singolo soggetto nel volume calibrato — che corrisponde al setup adottato in questa tesi — il problema si riduce a una selezione banale: in ogni frame e in ogni camera viene mantenuta la detection con il punteggio di confidenza più alto, ignorando eventuali detection parassite originate da riflessi, ombre mobili o osservatori accidentalmente in campo. Non è richiesto alcun algoritmo di tracking multi-persona o di re-identification.
3.8 Allineamento temporale frame-per-frame fra camere
La sincronizzazione descritta in Sezione 3.5 stabilisce il punto di inizio comune delle due tracce, ma non risolve un problema distinto: camere che acquisiscono a frame rate diversi producono griglie temporali che divergono progressivamente nel tempo. Il frame di indice \(k\) della camera A cade all’istante \(t = k/f_A\), mentre il frame di indice \(k\) della camera B cade a \(t = k/f_B\); con \(f_A \neq f_B\), lo scarto tra i due istanti cresce linearmente con \(k\) e non è recuperabile con un semplice offset intero [@pagnon_2022_joss_pose2sim]. La triangolazione DLT richiede che le osservazioni provenienti dalle diverse viste si riferiscano allo stesso istante fisico: usare il frame \(k\) di entrambe le camere senza ricampionamento equivale a triangolare punti che il soggetto occupava in momenti diversi, introducendo un errore sistematico che si somma all’errore di calibrazione.
L’entità del problema è tutt’altro che trascurabile anche per disallineamenti modesti. @jackson_2016_argus_audio_sync dimostrano che uno scarto di soli 0,5 frame tra le camere si traduce in un aumento di +0,54 px nell’errore medio di riproiezione e in un errore fino al 15% sulla seconda derivata temporale delle traiettorie — la grandezza dalla quale dipende direttamente la stima dell’accelerazione del centro di massa e, attraverso di essa, le forze di reazione al suolo (Sezione 3.12). Nei movimenti veloci come il push-off o il heel-strike del salto verticale, dove la cinematica articolare cambia di diversi gradi per frame, questi errori non sono trascurabili.
La soluzione apparentemente ovvia — ricampionare i video con un tool come ffmpeg portandoli al medesimo frame rate prima della pose estimation — è scorretta per una ragione di principio: il video è uno spazio discreto e finito, e qualsiasi operazione di ricampionamento è vincolata a questo limite. Quando si porta una traccia da \(f_\text{src}\) a \(f_\text{tgt} > f_\text{src}\), ogni frame aggiunto deve necessariamente essere o una copia del frame precedente (frame duplication) o una media pesata di due frame adiacenti (frame blending), nessuna delle quali rappresenta un’osservazione genuina dell’istante target.
Lavorare sulle coordinate \((x, y)\) dei keypoint stimate dalla pose estimation sposta il problema in uno spazio fondamentalmente diverso. Le traiettorie articolari umane sono funzioni continue del tempo; i campioni discreti forniti dalla pose estimation sono osservazioni rumorose di questa curva continua. Interpolando una funzione continua su questi campioni e valutandola all’istante target \(t^*\), si ottiene una stima dell’osservazione che si sarebbe avuta se quella camera avesse registrato un frame in quell’istante preciso. La Fig. 3.5 illustra il confronto tra le due strategie su una traiettoria reale di keypoint durante un CMJ.
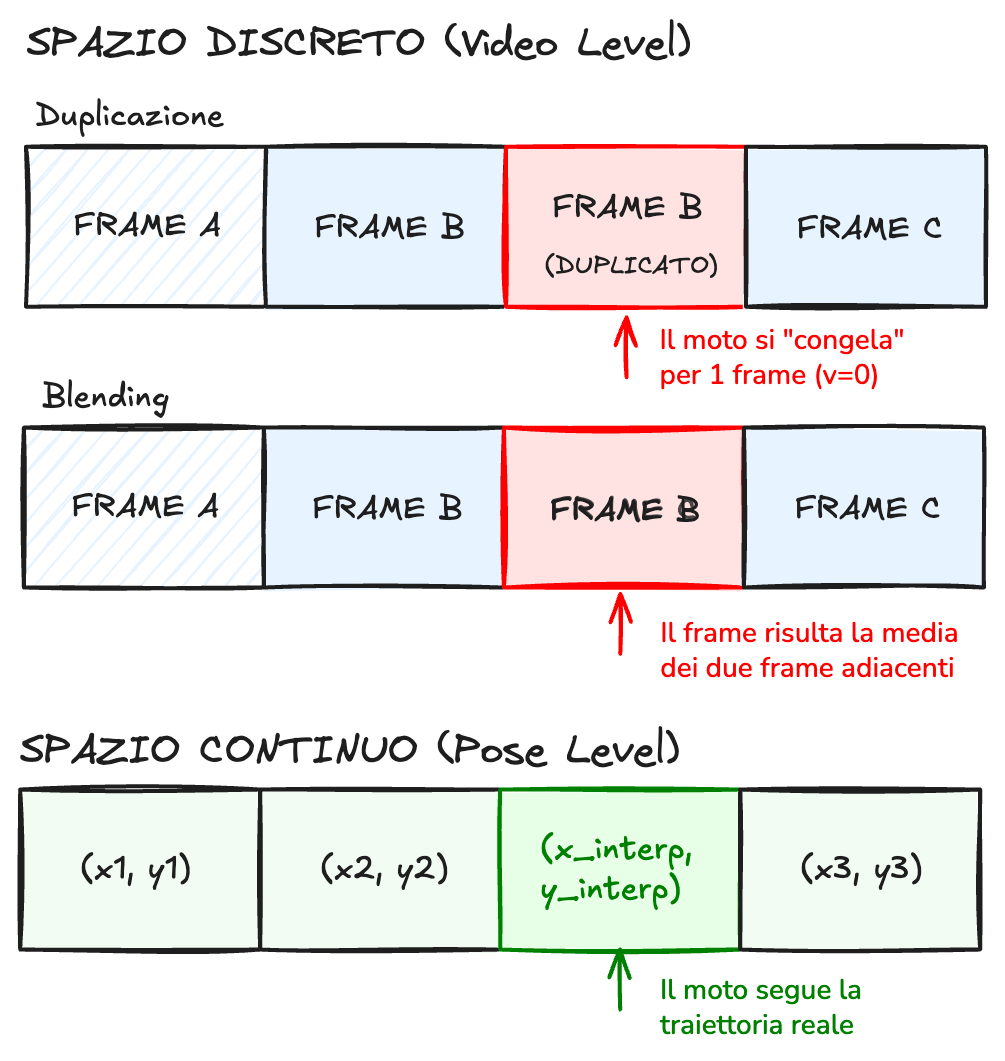
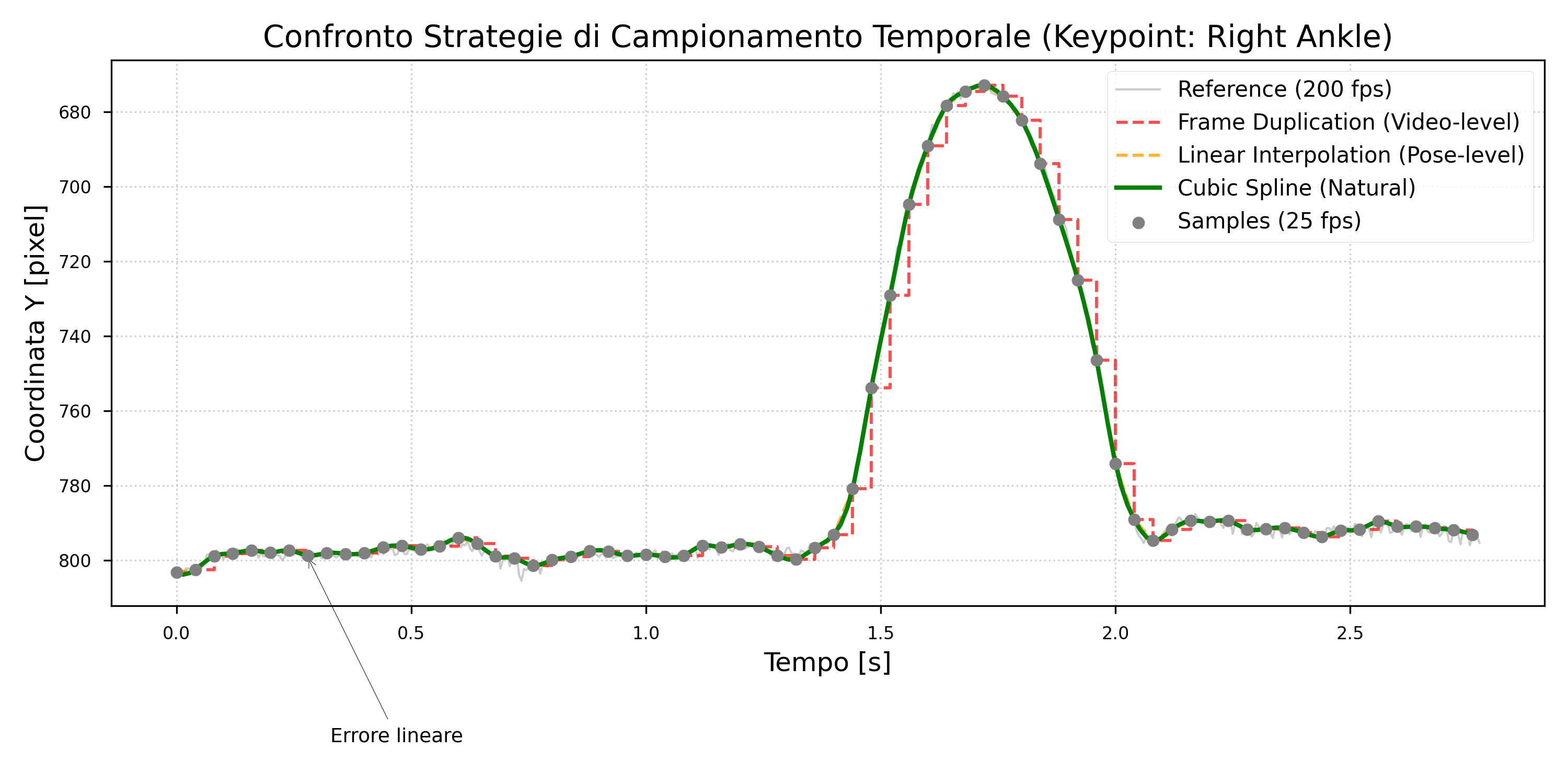
Il modulo pose2d_interpolation.py adotta come metodo operativo l’interpolazione lineare delle traiettorie 2D, calcolata via numpy.interp indipendentemente per ciascun asse di ciascun keypoint: il valore all’istante target \(t^*\) è la media pesata dei due campioni sorgente che lo circondano, \[x(t^*) = x_i + (x_{i+1} - x_i)\,\frac{t^* - t_i}{t_{i+1} - t_i}.\]
La scelta è una decisione metodologica. La griglia temporale comune verso cui si ricampiona è densa rispetto alla dinamica del moto — anche nelle fasi più veloci del CMJ il keypoint distale percorre tipicamente meno di un centimetro tra due frame adiacenti — e la differenza pratica tra una retta secante e una curva osculatrice è dell’ordine del decimo di pixel, dominata dal rumore stocastico della pose estimation. Inoltre, l’interpolazione lineare è l’unico schema causale a memoria minima eseguibile in tempo reale: richiede solo i due campioni che racchiudono l’istante target, a differenza di una stima cubica che richiederebbe di “conoscere il futuro”. Mantenere il metodo lineare garantisce che la pipeline rimane un limite teorico raggiungibile da un sistema reattivo, replicabile senza perdita da uno spotter robotico o da qualunque applicazione in cui la latenza è vincolante.
La spline cubica naturale (scipy.interpolate.CubicSpline, bc_type='natural') resta implementata nel modulo come strategia alternativa selezionabile via parametro method, ma in questa tesi ricopre il ruolo di baseline di confronto sperimentale: il suo utilizzo principale è quantificare quanto effettivamente si guadagni passando da \(C^0\) a \(C^2\) sulle traiettorie di una sessione reale, e — in subordine — fornire un fallback in casi patologici di ricampionamento massivamente upsampling (rapporti \(f_\text{tgt}/f_\text{src} > 4\)) per i quali la lineare comincia a esporre angoli visibili nei tracciati distali.
In entrambe le modalità, la confidenza del keypoint è interpolata linearmente e clampata a \([0, 1]\): rappresenta una stima probabilistica di visibilità, non una coordinata spaziale. Lo step ha una proprietà di idempotenza: se il rapporto \(f_\text{src}/f_\text{tgt}\) è unitario (tolleranza 0,5 fps), il modulo restituisce una copia invariata della sequenza sorgente.
La verifica primaria dell’allineamento è qualitativa: le traiettorie 2D dei keypoint distali — caviglia, polso — devono risultare visivamente continue prima e dopo lo step, senza gradini né “congelamenti” di un frame. La presenza di discontinuità residue segnala tipicamente una stima imprecisa del frame rate nativo di una delle camere, che introduce un errore sistematico nella costruzione della griglia temporale sorgente.
Il controllo quantitativo si articola su due fronti. Il primo è l’errore medio di riproiezione della triangolazione DLT calcolato con e senza lo step di allineamento FPF: la riduzione attesa è di circa 0,5–1 px sugli arti distali, che si muovono più velocemente e sono quindi più sensibili al disallineamento temporale residuo. Il secondo è il confronto diretto tra l’interpolazione lineare e la spline cubica sulle stesse traiettorie sorgente, valutato in termini di errore di riproiezione finale e di smoothness della seconda derivata della traiettoria 3D ricostruita: l’evidenza attesa, e che motiva la scelta del metodo principale, è che la differenza tra le due varianti su sessione_09 sia inferiore al rumore stocastico della pose estimation stessa.
3.9 Triangolazione 3D, filtraggio, marker augmentation
La ricostruzione delle traiettorie 3D a partire dai keypoint 2D estratti dalle multiple viste richiede una metodologia geometrica coerente. Il Direct Linear Transform (DLT) multi-vista risolve il sistema sovradeterminato che lega le coordinate immagine \((x_i, y_i)\) alle coordinate mondo 3D \((X, Y, Z)\) attraverso le matrici di proiezione di ogni camera [@pagnon_2022_joss_pose2sim]. Dato che ogni keypoint è visibile in almeno due viste (configurazione geometrica desiderata), il sistema è sovradeterminato: si minimizza l’errore ai minimi quadrati per ottenere la stima 3D più probabile. La qualità della ricostruzione è quantificata tramite errore di riproiezione, cioè la distanza in pixel tra il keypoint 2D osservato e la proiezione della stima 3D sulla vista originale. Quando questo errore supera una soglia (tipicamente 2–3 pixel per telecamere consumer), il keypoint è contrassegnato come outlier e scartato dalla traiettoria, evitando che frame rumorosi inquinino i passaggi successivi di filtraggio. L’output di questo step è un insieme di traiettorie 3D temporalmente contigue, pronto per il filtraggio.
Le traiettorie 3D contengono componenti di rumore derivanti sia dall’estrazione 2D (imprecisione del modello di pose estimation) sia dalla triangolazione (errore di localizzazione in 3D). Un filtro passa-basso elimina queste oscillazioni ad alta frequenza preservando le dinamiche biomeccaniche del movimento. La letteratura biomeccanica ha consolidato il filtro Butterworth 4° ordine con applicazione zero-lag (forward-backward filtering) come standard [@yu_1999_jab_butterworth; @templin_2024_frontiers_butterworth].
Si è scelto consapevolmente di applicare il filtraggio zero-lag pur consapendo della sua natura non-causale: il ricampionamento dei keypoint 2D mantiene la causalità operativa come scelta minimalista, ma il filtraggio 3D è una fase di post-processing off-line dove il ritardo di fase nullo è prioritario. L’applicazione zero-lag consente infatti di filtrare senza introdurre ritardo di fase, cruciale per il calcolo accurato di velocità e accelerazioni necessarie nei step successivi: un filtro causale standard introdurrebbe uno shift temporale sistematico tra il picco della traslazione e il picco della velocità derivata, compromettendo l’analisi dinamica [@butterworth_1930_wireless_engineer].
La frequenza di cutoff è scelta nell’intervallo 6–12 Hz a seconda della dinamica del movimento: per salti in estensione (ballistic phase veloce) si usa 10–12 Hz per preservare i transitori, mentre per movimenti più lenti si scende a 6–8 Hz. In questo lavoro è stata impiegata la configurazione 4° ordine zero-lag con cutoff 10 Hz, scelta standard per il salto verticale nella letteratura [@manal_2007_jbiomech_butterworth; @crenna_2021_sensors_butterworth]. Le traiettorie filtrate mantengono la dimensionalità di una traccia per marker, e i 26 keypoint anatomici della tassonomia HALPE sono ora liberi dal rumore di triangolazione ma ancora insufficienti per vincolare il modello muscoloscheletrico Rajagopal a 65 marker.
La ricostruzione 3D via Pose2Sim fornisce 26 keypoint sparsi (formato HALPE-26, inclusi caviglie, ginocchia, anche, gomiti, polsi, testa, spina dorsale). Questi 26 punti sono insufficienti per vincolare adeguatamente il modello muscoloscheletrico OpenSim Rajagopal (65+ marker anatomici): il gap topologico è del approx60%, con perdita critica di informazione su clavicole, spalle, vertebre intermedie, ossa del piede [@ergomechanic_2025_jbiomech_eng]. Il sintomo più critico non è solo l’errore medio, ma l’instabilità del solver: le correlazioni pelviche crollano, segnalando che il vincolo articolare è insufficiente per ancorare il bacino.
L’augmentation neurale risolve questo problema addestrando una rete ricorrente a mappare le 26 coordinate sparse alle 65+ coordinate dense anatomiche. L’architettura consolidata nello stato dell’arte è quella del Marker Enhancer di OpenCap [@falisse_2025_ieee_tbme_opencap]: due subnet indipendenti (upper body con 8 marker in output, lower body con 35 marker in output) riducono la dimensionalità rispetto a un singolo modello monolitico. Per ogni finestra temporale di T frame, la rete riceve i 26 keypoint × 3 coordinate e restituisce il marker set denso in coordinate anatomicamente coerenti.
La loss function è una weighted squared-error sui marker 3D di output:
\[\mathcal{L} = \frac{1}{D}\sum_{d=1}^{D} w_d\,(y_d - \hat{y}_d)^2 \tag{3.2}\]
dove \(D\) è il numero totale di coordinate xyz dei marker, \(w_d = 2\) per le coordinate dei sei marker del piede (calcagno, quinto metatarso, alluce per ciascun lato) e \(w_d = 1\) altrove [@falisse_2025_ieee_tbme_opencap]. Non si tratta di una loss pesata per DOF articolari: il doppio peso agisce direttamente sulla posizione dei marker distali per evitare il foot-skate, cioè lo slittamento artificiale del piede che si propagherebbe come errore sistematico nell’inverse dynamics. La rete è addestrata su un corpus di 16 dataset di motion capture marker-based, standardizzati tramite AddBiomechanics e OpenSim, per un totale di 1176 soggetti e 1433 ore di movimento con augmentation tramite rotazioni. AddBiomechanics è il layer di processing, non la sorgente esclusiva dei dati.
L’accuratezza risultante è 4.1° di errore angolare articolare medio (massimo 8.7°), misurata su una batteria di task: camminata 4.0°, squat 4.0°, sit-to-stand 3.9°, drop jump 4.6° [@falisse_2025_ieee_tbme_opencap]. Per il countermovement jump, il confronto esterno di @ruescas_nicolau_2024_sensors_augmentation riporta 3.39° con architettura Transformer — equivalente alla camminata (3.37°). Il task che degrada di più non è il CMJ ma la corsa (approx4.3°) e i movimenti fuori distribuzione [@ruescas_nicolau_2024_sensors_augmentation; @song_2023_jbiomech_markerless_8tasks]. Architetture alternative end-to-end (D3KE, BioPose) che bypassano il marker intermedio mostrano riduzioni dell’errore del 14–18%, ma richiedono dataset di training appaiati (2D→angoli) e comportano una complessità computazionale superiore [@bittner_2023_sensors_d3ke; @koleini_2025_wacv_biopose].
L’output finale di questo step è un file TRC (Tab-Separated Relative Coordinates), formato standard per le traiettorie di marker 3D in biomeccanica. Il file contiene N marker × T frame, con metadati nella intestazione: frequenza di campionamento, numero di frame, numero di marker, unità di misura (mm), nomi anatomici di ogni marker [@pagnon_2022_joss_pose2sim]. Il TRC viene sottoposto a verifiche di qualità — assenza di NaN, continuità spazio-temporale (nessun salto implausibile tra frame consecutivi), reprojection error entro soglia — che ne sanciscono l’idoneità all’ingresso nel solutore cinematico. La frequenza di campionamento è ereditata in modo trasparente dalle traiettorie filtrate: se il filtraggio ha operato a 60 Hz, il TRC ne mantiene 60 per secondo, evitando che lo step di augmentation introduca un ricampionamento implicito.
3.10 Modello muscoloscheletrico e scaling
Il modello muscoloscheletrico rappresenta il ponte tra i dati cinematici acquisiti (posizioni articolari in TRC) e le grandezze dinamiche ricercate (momenti articolari, forze di contatto). La scelta del modello e soprattutto il suo adattamento al soggetto specifico mediante il processo di scaling sono fattori determinanti per l’accuratezza di inverse kinematics e inverse dynamics.
Per questa tesi è stato adottato il modello Rajagopal 2016 [@rajagopal_2016_model], uno standard de facto in biomeccanica computazionale e il modello predefinito nel framework OpenSim [@delp_2007_opensim]. Il modello è un corpo intero con 29 gradi di libertà (DOF) distribuiti su articolazioni della colonna vertebrale, pelvi, e arti inferiori bilaterali, e descrive 80 muscoli il cui comportamento viene modellato mediante attuatori muscolari con dinamica Hill-type. La scelta di questo modello è motivata da tre criteri concreti: (1) versatilità comprovata per compiti di inverse kinematics, inverse dynamics e joint reaction analysis su movimenti dinamici come il salto verticale; (2) disponibilità di una documentazione estensiva nella letteratura biomeccanica e nelle community OpenSim; (3) integrazione stabile con il motore di simulazione Simbody sottostante a OpenSim, che garantisce coerenza numerica negli algoritmi di ottimizzazione.
Tuttavia, il modello generico è parametrizzato su dati antropometrici medi (lunghezze segmentali, masse, inerzie); questi parametri devono essere personalizzati al soggetto specifico mediante il processo detto scaling. Senza scaling, il risolutore di Inverse Kinematics cercherebbe di adattare la cinematica 3D misurata a un corpo di dimensioni scorrette, producendo elevati residui di posizionamento marker (RMSE marker molto alti) e joint angles biomeccanicamente non plausibili.
In questa tesi sono stati implementati tre metodi di scaling — standard, uniforme e segmentale — disponibili come varianti configurabili nel flusso di elaborazione. La scelta del metodo è guidata dal trade-off fra accuratezza della personalizzazione del modello e disponibilità dei dati antropometrici e cinematici, nonché dalla necessità di validare le scelte metodologiche mediante confronto sistematico.
Lo scaling standard utilizza il motore di scaling built-in di OpenSim, il quale combina dati globali del soggetto (massa corporea dichiarata e altezza antropometrica) con il file TRC per derivare fattori di scala segmentali in forma semi-automatica. Il fattore di scala globale è calcolato dalla relazione standard di OpenSim fra massa e lunghezza, \(k = (m_{\text{soggetto}} / m_{\text{modello}})^{1/3}\), e viene applicato uniformemente come base di partenza. Questo metodo è quello predefinito in OpenSim e in framework derivati come Pose2Sim, e rappresenta il baseline metodologico verso il quale confrontare i risultati ottenuti con metodi più elaborati.
Lo scaling uniforme applica un fattore di scala omogeneo a tutti i segmenti corporei, preservando le proporzioni segmentali del modello generico. È implementato come fallback conservativo quando il motore di scaling automatico di OpenSim non è disponibile o è numericamente instabile, come nel presente lavoro con dati markerless. Il metodo legge la massa corporea dichiarata e l’altezza antropometrica del soggetto, calcola il fattore di scala globale \(k = (m_{\text{soggetto}} / m_{\text{modello}})^{1/3}\), e lo applica uniformemente a tutti gli elementi geometrici del modello (lunghezze segmentali, posizioni dei centri di massa, fattori di scala della geometria visibile). Le masse dei segmenti vengono quindi ridistribuite per normalizzare la massa totale del modello al valore dichiarato dal soggetto. Questo approccio è computazionalmente economico e non richiede marker aggiuntivi, rendendo il workflow semplice e robusto. Lo svantaggio principale è l’ignoranza della variabilità inter-individuale nelle proporzioni segmentali: due soggetti della stessa massa e altezza possono avere rapporti molto diversi fra lunghezza del bacino e quella degli arti.
Lo scaling segmentale segue un principio opposto e fortemente data-driven: ricava la lunghezza reale di ogni singolo segmento corporeo dal dato sperimentale disponibile, cioè dalle posizioni 3D dei marker nel file TRC (di posa di calibrazione o riposo). Per ciascun segmento, calcola il fattore di scala individuale \(k_i = L_{\text{misurato},i} / L_{\text{modello},i}\) sulla base di una catena di giunti definita nel modello e di marker endpoint opzionali nel corpo terminale del segmento. L’algoritmo segmentale è parametrico: per ogni segmento corporeo (femore destro/sinistro, tibia, tronco, avambraccio, ecc.) si specifica una lista ordinata di nomi di giunti la cui catena di traslazioni descrive geometricamente la lunghezza; i fattori calcolati vengono applicati segmento per segmento al modello generico, preservando la coerenza anatomica. Le masse dei segmenti vengono poi ridistribuite per conservare la massa corporea totale dichiarata, utilizzando gli stessi rapporti di densità segmentale del modello generico. Questo approccio sfrutta appieno l’informazione contenuta nei dati cinematici 3D e produce una personalizzazione molto più accurata del modello rispetto al metodo uniforme. Un’implementazione iterativa e sofisticata di questo concetto, il tool AST (Automated Scaling Tool) [@dipietro_2024_ast_scaling], dimostra per via empirica che il ciclo marker-correction + re-scaling + IK converge sistematicamente a residui molto inferiori rispetto al metodo uniforme, fornendo al contempo criteri espliciti per decidere, segmento per segmento, se usare fattori basati su marker o fattori costanti.
L’implementazione concreta dello scaling segmentale adottata in questa tesi utilizza il modulo lib/scaling.py, che implementa il metodo in forma deterministica e parametrica: legge le lunghezze segmentali dal file TRC di output della sezione precedente (§3.9), che include i 65 marker virtuali ottenuti mediante marker augmentation; per ogni segmento definito nel file di configurazione, estrae la catena di giunti correspondente dal modello OpenSim e calcola la lunghezza modello come somma vettoriale delle traslazioni parent-frame; misura la lunghezza sperimentale come P95 della distanza 3D fra marker prossimali e distali nel TRC, una metrica robusta al rumore e alle frame dropouts; calcola il fattore di scala \(k_i = L_{\text{TRC},i} / L_{\text{modello},i}\); applica il fattore a tutti i Body associati al segmento nella definizione del modello; applica il fattore alle traslazioni dei joint nella catena; scala le posizioni dei marker associati ai body scaled; infine normalizza le masse corporee per mantenere il valore dichiarato. Una scelta implementativa cruciale è stata l’abbandono del built-in OpenSim Scale Tool con loop interno di ottimizzazione (“automatic scaling” nella versione 4.4), che si è rivelato numericamente instabile nel contesto dei nostri dati markerless: la convergenza non si raggiungeva nemmeno dopo 50 iterazioni, spesso per divergenza negli assi trasversali (tx, tz) della pelvi. Il metodo segmentale deterministico garantisce riproducibilità garantita, controllo totale sui singoli parametri di scaling, e assenza di fallimenti di convergenza.
Questi tre metodi sono integrati nel flusso di elaborazione come dimensioni di variazione: la pagina di configurazione “Crea Varianti” (§3.15) consente di selezionare uno o più metodi di scaling da applicare al trial in analisi, e il DAG di elaborazione genera automaticamente le varianti. Un trial base con tre metodi di scaling produce tre varianti parallele che condividono tutta l’elaborazione precedente (video, calibrazione, pose 2D/3D, sincronizzazione frame rate) e divergono soltanto a partire dalla fase di scaling.
Il modello scaled è quindi l’input determinante per la fase di Inverse Kinematics (§3.11), dove i 65 marker 3D nel file TRC vengono adattati minimizzando l’errore di posizionamento rispetto ai vincoli di dinamica articolare del modello personalizzato.
3.11 Inverse Kinematics
La fase di Inverse Kinematics (IK) riceve come input il modello muscoloscheletrico scaled (§3.10) e il file TRC contenente i 65 marker anatomici ricostruiti in 3D dalla fase precedente (§3.9). L’obiettivo è minimizzare l’errore di posizionamento tra i marker virtuali del modello e le posizioni misurate nel file TRC, rispettando i vincoli articolari del modello Rajagopal [@rajagopal_2016_model]. La minimizzazione è governata da un file di configurazione XML (setup_ik.xml) che specifica tre categorie di parametri critiche per la stabilità numerica e la fedeltà ai dati: (1) i pesi marker, assegnati diversamente a seconda dell’importanza biomeccanica del punto (marker sul ginocchio e caviglia, chiavi per il nostro focus sulle forze articolari, ricevono peso più elevato rispetto a marker secondari come il pollice o i marker toraci); (2) il filtro temporale, di solito un filtro Butterworth passa-basso di ordine 4 con frequenza di cutoff nell’intervallo 6–12 Hz, che attenua il rumore cinematico ad alta frequenza preservando la dinamica lenta del movimento; (3) il range temporale e le tolleranze di convergenza, che confinano la minimizzazione a sotto-intervalli specifici del trial e stabiliscono criteri di arresto iterativo. Questa strutturazione consente di controllare il trade-off fra fedeltà ai dati cinematici grezzi e stabilità della soluzione, evitando divergenze numeriche su gradi di libertà scarsamente osservati dai dati (ad es. il bending del busto, dove il TRC offre poca informazione diretta).
L’output della fase IK è un file di motion nel formato STO (Storage), la rappresentazione tabulare standard di OpenSim per time series [@delp_2007_opensim]. Il file contiene una riga per ogni istante temporale del trial e una colonna per ogni grado di libertà del modello. Per un modello Rajagopal, questo significa 62 coordinate: i 29 DOF articolari rappresentati in gradi sessagesimali (standard della biomeccanica), più coordinate ausiliarie di velocità e accelerazione. Le colonne sono ordinate gerarchicamente per corpo (pelvis → femore sx/dx → tibia → piede, ecc.), facilitando l’ispezione visiva e il debugging. Un controllo di qualità fondamentale sulla soluzione IK è la verifica che i range articolari rimangono entro i limiti fisiologici definiti nel modello: il ginocchio non deve superare l’estensione completa, l’anca deve mantenere ROM ragionevole per il movimento umano, le caviglie devono rispettare i vincoli legamentosi. Inoltre, viene ispezionato il residuo IK, cioè l’errore RMS medio fra la posizione dei marker prevista dal modello fitted e la posizione effettiva misurata nel TRC; un residuo elevato (>1.5 cm) indica un fit scadente e suggerisce problemi nel TRC o nel setup di scaling e filtraggio precedenti. Nel flusso di lavoro operativo, file MOT con residui accettabili (<1 cm) procedono agli step successivi (Inverse Dynamics, Joint Reaction Analysis), mentre file problematici vengono investigati e, se necessario, ri-processati con parametri IK modificati.
Una delle leve sperimentali della tesi è il confronto sistematico fra variant che differiscono in frame rate: lo stesso trial acquisito ed elaborato a 25, 50, 100 fps genera tre file MOT con timeline diverse (N, 2N, 4N frame rispettivamente). Per permettere confronti equi della cinematica e delle forze articolari fra questi variant, i file MOT di bassa frequenza vengono ricampionati a una griglia temporale comune (ad es. 100 fps) mediante spline cubica naturale C². L’upsampling post-IK preserva la continuità geometrica e delle derivate prime (velocità articolari), minimizzando artefatti numerici che potrebbero comparire in stadi successivi di Inverse Dynamics dove le derivate sono critiche. Questa procedura è analoga al ricampionamento dei keypoint 2D discusso in §3.8: invece di operare a livello di video (che comporterebbe perdita d’informazione), il ricampionamento avviene sulle curve cinematiche esplicite post-IK, dove l’interpolazione è fisicamente significativa. L’output è un file MOT upsampled che mantiene la stessa struttura del file nativo, ma con frame rate unificato, permettendo normalizzazioni statistiche e confronti diretti in fase di analisi dei risultati (Cap. 4).
3.12 Stima delle forze di reazione al suolo
Entrambi i metodi di stima descritti in questa sezione si fondano sulla medesima identità meccanica: applicando la seconda legge di Newton all’intero corpo del soggetto come sistema isolato, la componente verticale della forza di reazione al suolo eguaglia il prodotto della massa corporea per l’accelerazione verticale del baricentro aumentata dell’accelerazione di gravità:
\[\text{GRF}_y(t) = m \cdot \bigl(\ddot{y}_\text{CoM}(t) + g\bigr) \tag{3.3}\]
[@linthorne_2001_vertical_jump]. La stima della GRF si riduce quindi a determinare la traiettoria temporale dell’accelerazione verticale del baricentro corporeo, grandezza non direttamente osservabile ma inferibile dalla cinematica tridimensionale acquisita nei passi precedenti.
La stima dal punto bacino approssima il baricentro corporeo con la posizione verticale del centro dell’anca: il punto-chiave corrispondente nel formato HALPE_26 (§Sezione 3.7) già presente nelle traiettorie tridimensionali prodotte dalla triangolazione (§Sezione 3.9). Questo approccio opera senza richiedere un modello muscoloscheletrico: l’unico input è la traiettoria 3D già disponibile, e la stima della GRF può precedere l’eventuale fase di adattamento del modello al soggetto e di analisi cinematica inversa.
La Fig. 3.6 illustra la posizione del punto bacino sul soggetto in una posa rappresentativa, con la curva di traiettoria verticale estratta da un trial di sessione_09.
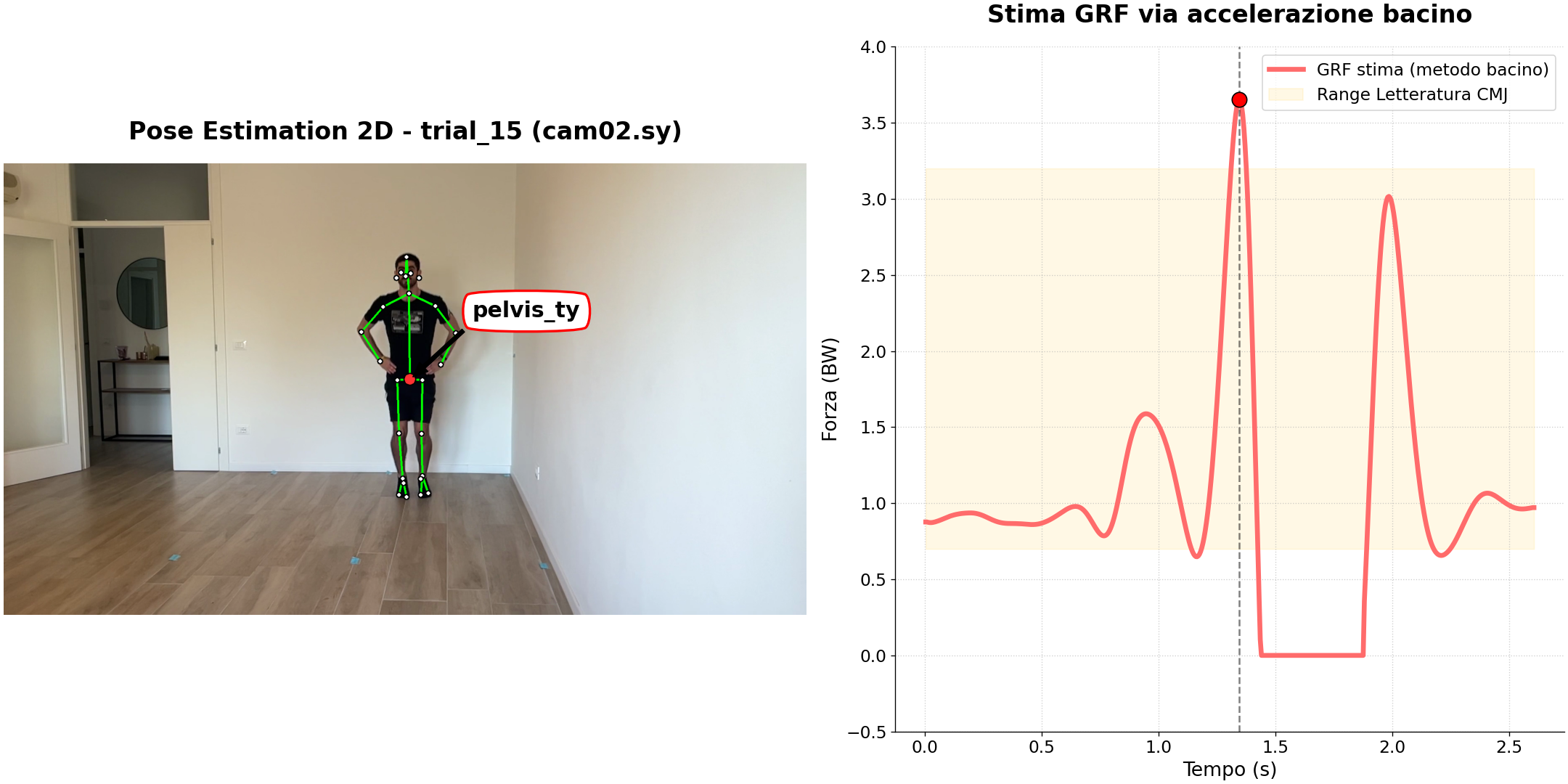
La traiettoria verticale del bacino viene derivata due volte numericamente mediante differenze finite centrali del secondo ordine, uno schema che garantisce accuratezza al secondo ordine senza richiedere fotogrammi futuri. Il segnale di accelerazione è filtrato con un filtro di Butterworth del quarto ordine a fase zero per attenuare l’amplificazione del rumore introdotta dalla doppia derivazione. I valori di GRF negativi fisicamente impossibili — che possono comparire in prossimità del decollo — vengono soppressi ponendoli a zero.
L’assunzione che la posizione del bacino sia una buona approssimazione del baricentro corporeo è accettabile nelle fasi di stazione eretta, ma diventa sistematicamente inaccurata durante la flessione del contrommovimento: la discrepanza verticale può raggiungere 5–10 cm e si traduce direttamente in un errore sull’accelerazione stimata.
La stima del CoM (Centro di Massa) supera questa limitazione calcolando il baricentro corporeo direttamente all’interno del modello muscoloscheletrico personalizzato. Il modello Rajagopal personalizzato al soggetto (§Sezione 3.10) descrive ogni segmento corporeo con la propria massa e la propria geometria; il baricentro totale è la media pesata in massa delle posizioni dei centri di massa dei singoli segmenti, una grandezza fisicamente più accurata della semplice posizione del punto bacino perché integra la distribuzione di massa dell’intero corpo — tronco, arti superiori e testa inclusi. OpenSim espone questo calcolo attraverso l’analisi BodyKinematics, che accetta come input la cinematica articolare prodotta dalla fase di analisi cinematica inversa (§Sezione 3.11) e restituisce la traiettoria temporale del baricentro globale \(\mathbf{r}_\text{CoM}(t)\) fotogramma per fotogramma.
La Fig. 3.7 illustra la differenza di posizione tra il punto bacino e il baricentro reale del modello in tre fasi rappresentative del CMJ: il contrommovimento profondo, l’istante dello stacco e l’apice del volo.

Come illustra la Fig. 3.7, la discrepanza è massima nella fase di contrommovimento profondo: la flessione delle anche e delle ginocchia abbassa il bacino, mentre il tronco e gli arti superiori — che contribuiscono in misura significativa alla massa totale — rimangono ad altezza superiore, alzando il baricentro globale rispetto al punto bacino. La traiettoria \(y_\text{CoM}(t)\) risulta sistematicamente più alta di \(y_\text{pelvis}(t)\) nella fase eccentrica, per poi convergere nella fase di volo in cui il corpo è esteso e la differenza tra i due punti si annulla quasi del tutto.
L’algoritmo di stima segue lo stesso schema della stima dal punto bacino: la coordinata verticale del baricentro viene derivata due volte con differenze finite centrali del secondo ordine su una griglia temporale che dipende dal frame rate del trial — e, nelle varianti upsampled (§Sezione 3.11), può essere stata ricampionata a una griglia più fitta. Il segnale è poi filtrato con Butterworth del quarto ordine a fase zero e la GRF è calcolata come Eq. 3.3, con i valori negativi soppressi a zero [@colyer_2023_markerless_grf].
La differenza pratica tra i due metodi si manifesta soprattutto nel profilo della fase eccentrica: la traiettoria CoM segmentale, meno influenzata dalla flessione delle anche, produce un’accelerazione verticale inizialmente meno negativa e di conseguenza una depressione della GRF meno marcata. Il profilo complessivo risulta più vicino ai profili attesi dalla letteratura per il CMJ [@linthorne_2001_vertical_jump], dove la riduzione della GRF durante la fase eccentrica riflette il cambio di direzione del baricentro reale, non un artefatto dell’approssimazione adottata. Il confronto quantitativo tra i due metodi e il profilo di riferimento è riportato in Sezione 4.6.
Il profilo della forza di reazione al suolo nel CMJ assume una forma caratteristica e ben documentata: una prima fase di riduzione della GRF durante la frenata eccentrica, seguita da una risalita progressiva che culmina in un picco propulsivo marcato nella fase concentrica [@linthorne_2001_vertical_jump]. I valori di riferimento per atleti in condizioni controllate indicano un primo picco nell’intorno del peso corporeo nella fase iniziale del contrommovimento, una depressione che scende fino a circa 0.7–0.8 volte il peso corporeo nella fase eccentrica, e un secondo picco compreso tra 2 e 3 volte il peso corporeo nella propulsione; nei saltatori di livello élite il picco propulsivo può superare questi valori [@mcmahon_2018_cmj_force_phases]. Questo profilo ha costituito il riferimento qualitativo per la validazione dei risultati lungo tutta la catena di elaborazione: la corrispondenza tra la forma stimata e quella attesa ha guidato le scelte di configurazione del filtraggio e ha permesso di distinguere artefatti numerici da fenomeni fisiologici reali. Il confronto formale tra le stime ottenute con i due metodi e il profilo di riferimento è riportato in Sezione 4.6.
Tra le alternative metodologiche considerate nella definizione della pipeline figura la simulazione dinamica tramite OpenSim Moco [@dembia_2020_opensim_moco], approccio che stima le forze di reazione al suolo come parte di un problema di ottimizzazione diretta che risolve simultaneamente cinematica, dinamica e attivazione muscolare — rendendolo teoricamente il più accurato tra i candidati esaminati. La sua integrazione nella pipeline operativa del presente lavoro non è stata perseguita; le ragioni di questa scelta e una valutazione delle condizioni che ne limitano l’applicabilità nel contesto markerless sono discusse in Sezione 5.4.
3.13 Inverse Dynamics
L’Inverse Dynamics richiede che la forza di reazione al suolo sia assegnata separatamente ai due piedi come carichi esterni distinti; le stime ottenute dai due metodi descritti sono tuttavia GRF totali, prive di informazione sulla distribuzione bilaterale. Nel CMJ a due gambe, è ragionevole assumere che il carico sia distribuito in modo sostanzialmente uguale tra arto sinistro e arto destro: la GRF verticale totale viene pertanto dimezzata e assegnata simmetricamente ai due ExternalLoad di OpenSim, ciascuno agente sul punto di contatto del piede corrispondente. Questa assunzione semplifica la formulazione del problema di dinamica inversa e produce momenti articolari bilateralmente coerenti in assenza di misurazioni indipendenti per ciascun arto.
La configurazione dell’Inverse Dynamics in OpenSim richiede due file distinti: il file di setup XML dell’analisi e il file external_loads.xml che definisce come le forze di reazione al suolo vengono applicate al modello. Il file external_loads.xml specifica due carichi esterni — uno per ciascun piede — collegati ai file STO prodotti dalla stima GRF; il punto di applicazione è il calcagno di ciascun arto (body calcn_l e calcn_r nel modello Rajagopal). Il file di setup dell’analisi indica il percorso al modello personalizzato, il file di cinematica (.mot), il range temporale e la cartella di destinazione dei risultati.
L’Inverse Dynamics calcola i momenti generalizzati differenziando due volte nel tempo la cinematica articolare: il rumore residuo presente nelle traiettorie angolari prodotte dall’analisi cinematica inversa viene amplificato quadraticamente con la frequenza, producendo picchi di momento non fisiologici che compromettono l’interpretazione dei risultati. Per contenere questo effetto, le traiettorie del file .mot vengono filtrate con un filtro di Butterworth del quarto ordine a fase zero prima di essere passate all’analisi, adottando una frequenza di taglio conservativa non superiore a 5 Hz, adeguata a task esplosivi come il CMJ in cui il contenuto spettrale fisiologico rilevante è concentrato nelle basse frequenze [@manal_2007_jbiomech_butterworth]. La stessa frequenza di taglio viene applicata al segnale GRF, in modo da mantenere coerenza dinamica tra le forze esterne, la cinematica: una discrepanza nelle bande di taglio tra i due segnali si manifesta come residui sistematicamente elevati al bacino, il principale indicatore di qualità diagnostico dell’analisi [@colyer_2023_markerless_grf].
L’output dell’analisi è un file .sto che riporta, per ogni fotogramma del trial, i momenti generalizzati associati a ciascun grado di libertà del modello. I momenti di interesse primario per questa tesi sono quelli di flessione e di estensione al ginocchio, all’anca e alla caviglia, bilateralmente, che costituiscono l’input per la successiva Joint Reaction Analysis (Sezione 3.14). Parallelamente, OpenSim calcola i residui al bacino — forze e momenti residui sulla radice del modello che rappresentano la quota di forza non spiegata dalla GRF applicata — e li riporta nello stesso file di output: valori inferiori a 5 N e 5 Nm sono considerati accettabili e indicano buona coerenza dinamica tra cinematica, modello e stima delle forze esterne; valori superiori segnalano criticità nella qualità della GRF o nella calibrazione del modello e guidano l’iterazione diagnostica sul trial [@delp_2007_opensim].
3.14 Joint Reaction Analysis
La Joint Reaction Analysis (JRA) costituisce l’outcome finale della pipeline: stima le forze di contatto che agiscono all’interno dell’articolazione del ginocchio durante il CMJ, una grandezza che l’Inverse Dynamics da sola non è in grado di fornire. I momenti articolari calcolati nella fase precedente (Sezione 3.13) descrivono il momento risultante attorno a ciascun asse articolare, ma non decompongono tale momento nelle forze di compressione e di taglio che caricano effettivamente le strutture intra-articolari — cartilagine, menischi, legamenti. Questa distinzione è rilevante sia in ambito clinico che sportivo: le forze di compressione tibio-femorale durante un salto verticale possono superare di due o tre volte il valore del momento articolare corrispondente [@cleather_2013_hip_knee], e la loro entità è un indicatore di rischio per patologie degenerative e per la valutazione del recupero post-infortuni. Stimarle in un contesto completamente markerless e senza pedana di forza rappresenta il contributo di proof-of-concept di questa tesi.
La JRA in OpenSim richiede che il sistema dinamico sia completamente bilanciato: per ogni grado di libertà del modello deve esistere una sorgente di forza o di momento coerente con la dinamica imposta dalla cinematica e dalle forze esterne. In un modello muscoloscheletrico completo, questo bilancio è garantito dai muscoli; nella pipeline del presente lavoro, priva di stima delle attivazioni muscolari, il problema è sotto-determinato e richiederebbe di risolvere la ridondanza muscolare — un’operazione computazionalmente costosa e dipendente dalle ipotesi sul criterio di ottimizzazione adottato. L’approccio seguito è mutuato da OpenCap [@uhlrich_2023_opencap]: i muscoli del modello vengono disabilitati e sostituiti da un CoordinateActuator per ciascun grado di libertà, attuatori ideali capaci di produrre esattamente il momento richiesto senza inerzia propria. Un PrescribedController prescrive a ciascun attuatore il momento generalizzato corrispondente estratto dal file di output dell’ID, fotogramma per fotogramma. Il risultato è un modello che riproduce fedelmente la cinematica e la dinamica osservata senza richiedere la soluzione del problema di ridondanza muscolare, e che può essere sottoposto all’analisi di reazione articolare.
Il file di configurazione setup_jra.xml specifica i parametri dell’analisi: il modello modificato con gli attuatori di riserva, il file di cinematica, il file di controlli (momenti prescritti dall’ID), il range temporale del trial e l’articolazione di interesse. Per il ginocchio, la coppia di corpi analizzata è il femore come corpo genitore e la tibia come corpo figlio, con l’output espresso nel sistema di riferimento locale del corpo figlio — convenzione che permette di leggere direttamente la componente assiale della forza (compressione lungo l’asse longitudinale della tibia) e le componenti di taglio nel piano trasversale. I CoordinateActuator vengono aggiunti programmaticamente al modello in memoria prima di avviare l’analisi, senza modificare il file .osim originale del soggetto, preservando la separazione tra il modello calibrato al soggetto e la configurazione specifica dell’analisi JRA.
L’analisi produce un file joint_reaction.sto che riporta, per ogni fotogramma del trial, le componenti cartesiane della forza (Fx, Fy, Fz) e del momento (Mx, My, Mz) di reazione al ginocchio nel sistema di riferimento del corpo figlio. Le grandezze di interesse primario sono la forza di compressione tibio-femorale — componente diretta lungo l’asse longitudinale della tibia, tipicamente dominante durante la fase propulsiva del CMJ — e la forza di taglio antero-posteriore, associata al carico sui legamenti crociati. I valori sono espressi in Newton e normalizzabili rispetto al peso corporeo del soggetto per consentire confronti tra varianti e con i riferimenti bibliografici [@cleather_2013_hip_knee]. Il picco di compressione articolare atteso durante il CMJ si colloca nell’ordine di 3–6 volte il peso corporeo, con variabilità legata alla tecnica di salto e al livello atletico del soggetto.
La stima ottenuta con questo approccio è per costruzione una stima minimale delle forze di contatto articolare reali. Disabilitando i muscoli e sostituendoli con attuatori ideali, si trascura la co-contrazione muscolare antagonista: in condizioni reali, l’attivazione contemporanea di agonisti e antagonisti produce forze di compressione articolare significativamente superiori a quelle necessarie per il solo bilanciamento dinamico [@cleather_2013_hip_knee]. I valori prodotti dalla JRA rappresentano quindi il limite inferiore teorico della forza articolare compatibile con la cinematica osservata, ma non con la fisiologia muscolare completa. Questa limitazione è condivisa con tutti gli approcci ID-based alla JRA e non inficia la validità dei confronti comparativi tra varianti della stessa pipeline — dove il sistema di stima è identico e le differenze relative rimangono significative — ma esclude l’uso dei valori assoluti per diagnosi cliniche o per il confronto diretto con misurazioni in vivo tramite endoprotesi strumentate. L’estensione a una stima muscle-driven è indicata come direzione di sviluppo in Sezione 5.4.
3.15 Sistema di varianti e DAG
Una variante è una combinazione specifica di parametri di elaborazione che differisce dal trial base in una o più dimensioni: frame rate, risoluzione video, metodo di scaling del modello muscoloscheletrico, o metodo di stima delle forze di reazione al suolo. Lo scopo del sistema di varianti non è replicare dati, bensì esplorare sistematicamente lo spazio parametri per identificare quale configurazione rappresenta il miglior compromesso fra qualità dei risultati e risorse computazionali/acquisitive richieste. La domanda guida è: è possibile ottenere risultati qualitativamente equivalenti a una configurazione ideale (ad esempio 1080p a 100 fps) usando un hardware consumer a risorse inferiori (480p a 25 fps)? Il sistema mette a disposizione preset predefiniti — confronto frame rate, confronto risoluzione, confronto metodi GRF, matrice completa — che generano automaticamente tutte le combinazioni desiderate a partire da una lista di dimensioni e valori. Ogni variante riceve una cartella sul disco con una copia (o collegamento simbolico) dei video ridimensionati, uno stato di esecuzione tracciato, e parametri ereditati dal trial base che vengono via via riscritti.
Elaborare 100+ varianti sequenzialmente dalla calibrazione fino alla Joint Reaction Analysis comporterebbe un costo computazionale proibitivo. Un Directed Acyclic Graph (DAG) identifica e riusa automaticamente i nodi computazionali condivisi fra varianti diverse. Due varianti che differiscono soltanto nel metodo di stima GRF leggono gli stessi video, eseguono la stessa Pose2Sim, le stesse pose 3D, lo stesso scaling e lo stesso Inverse Kinematics; divergono unicamente a partire dal passo di stima GRF in poi. Il DAG raggruppa le varianti per “sorgente video” (combinazione fps + risoluzione) e un solo nodo Pose2Sim condiviso produce le traiettorie 3D, che vengono poi lette in parallelo da nodi distinti di GRF/ID/JRA per ogni variante del gruppo. Ogni nodo nel DAG possiede uno stato persistito in variant_dag.json — pending, running, done, oppure error — insieme a timestamp, durata di esecuzione, e messaggi di errore diagnostici. Questa persistenza permette di riprendere l’esecuzione interrotta senza rifare lavoro già completato, e di tracciare tempi e performance per ogni step (Fig. 3.8 mostra un esempio semplificato). L’architettura risultante supporta sia esecuzione sequenziale che parallela di nodi indipendenti, adattandosi alle risorse disponibili della macchina host.
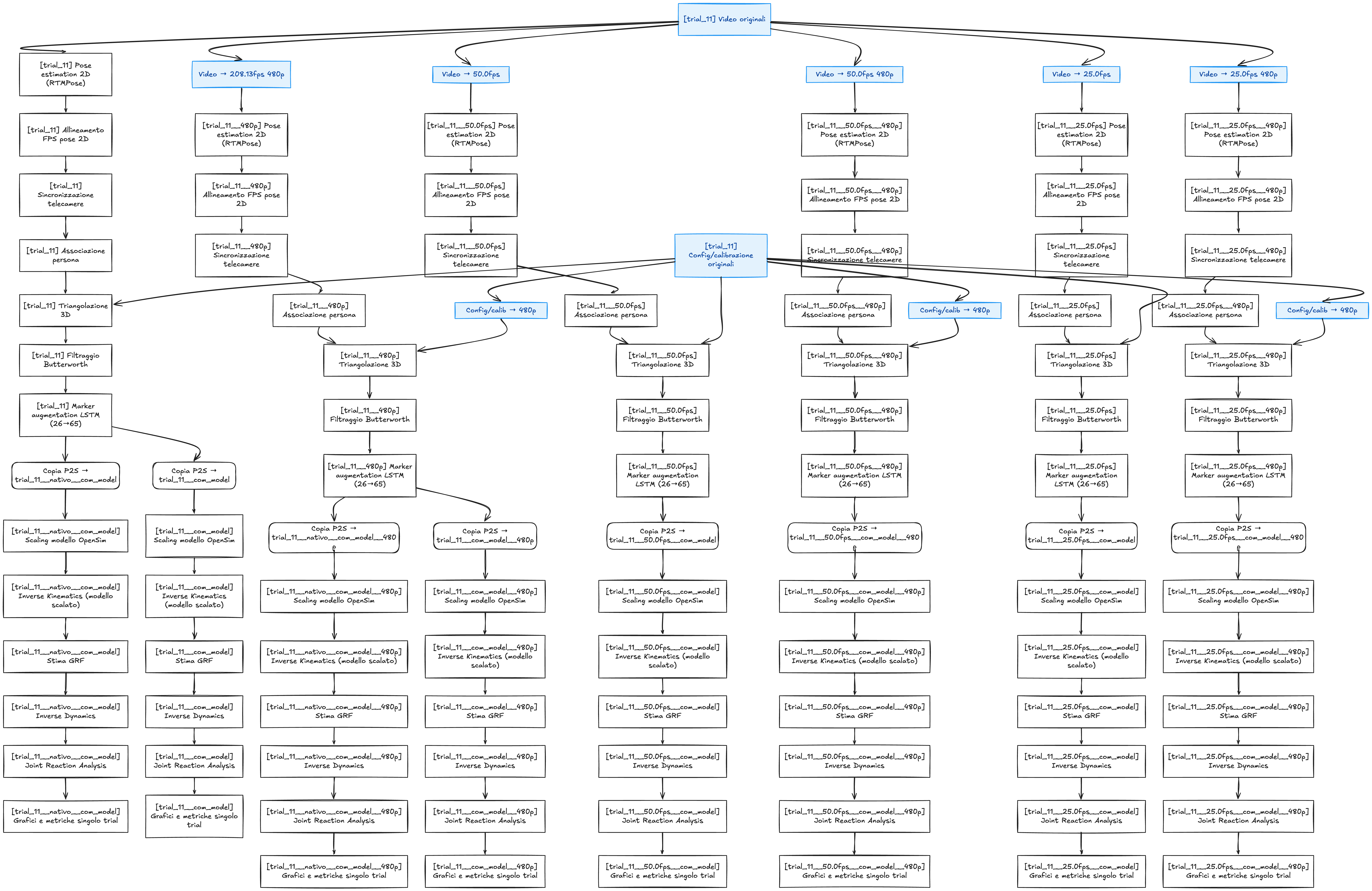
Il nome della cartella variante codifica esattamente quali parametri sono stati modificati rispetto al trial base, secondo una convenzione rigida. Il formato è trial_XX__tag1__tag2__tag3, dove i tag rappresentano solo le dimensioni che differiscono da quella base. Ad esempio: trial_03__50fps per frame rate ridotto, trial_03__50fps__480p per risoluzione ridotta, trial_03__50fps__480p__com_model per metodo GRF diverso. Il separatore doppio underscore __ garantisce disambiguazione univoca.
La tracciabilità completa di ogni variante è garantita da tre file di metadata che accompagnano l’esecuzione. Il file variant_family.json, collocato nel trial base, contiene il catalogo di tutte le varianti della famiglia: per ciascuna, i parametri esatti, i comandi pipeline da eseguire, e lo stato di creazione. Il file variant_info.json, presente in ogni cartella variante, replica il sottoinsieme di parametri di quella variante, aggiunge lo stato di avanzamento (quali step sono stati completati), e traccia timestamp di creazione e eventuali note operative. Il file variant_dag.json, al livello soggetto, mantiene il grafo DAG completo con lo stato di ogni nodo computazionale e le dipendenze fra essi. Lo scopo di questa struttura di tracciamento è duplice: da una parte, garantisce ripetibilità — chiunque nel team può rigenerare la stessa variante da variant_info.json senza ambiguità, anche anni dopo; dall’altra, supporta il processo decisionale di validazione. Durante la fase di analisi risultati (Cap. 4), i file di metadata permettono di raggruppare varianti per dimensione di confronto e di confrontare i risultati cross-variant in modo sistematico, identificando quale configurazione parametrica rappresenta il miglior compromesso fra qualità e praticità acquisitiva. Ad esempio, se le curve di GRF e i momenti articolari di trial_03__25fps si discostano di meno del 5% da trial_03__100fps, il verdetto è che 25 fps è sufficiente per questa applicazione, giustificando l’uso di hardware consumer con frame rate inferiore. La catena di decisioni — dalla scelta dei parametri al verdetto finale — rimane quindi documentata, tracciabile, e aperta al riesame critico durante la scrittura del capitolo 5.